synthesis notes_GlossaryIndex
Index
- Was tun Computer?
- Kommunikation mit Computern
- Plaintext
- Dateien
- Programmiersprache
- Hilfe bei Computerproblem
- Warum C?
- Compiler
- Algorithmus
- Variable
- Zuweisungen
- Ausdrücke
- Schleifen
- Quellcode kommentieren
- Debugging
- Fehlertypen
- Block
- Bedingte Anweisung
- Boolean Expressions
- Funktion
- Rekursion
- Modularisierung
- Speicher
- Hexadezimal
- Speicheradresse
- Array
- Dynamische Speicherallokation
- Fehlerbehandlung
- String
- Ein- und Ausgabekanäle
- Git
- Pseudocode
- insertion sort
- Sortieralgorithmen
- selection sort
- bubble sort
- count sort
- Komplexität
- Zeitkomplexität
- Raumkomplexität
- Topographie
- Einfache Datenstrukturen
- linked list
- double linked list
- Stack
- Queue
- Dynamische Datenstrukturen
- Record
- tree
- C-Streams
- Unix Befehle
- MergeSort
- Logarithmus dualis
- Wie beweist man die Korrektheit eines Algorithmus?
- Korrektheitsbeweis
- Heap
- HeapSort
- AVL-tree
- divide & conquer
- Quicksort
- radix sort
Glossary
- speicher Informationen/Daten in Dateien
- befolgen exakt Anweisungen
Kommunikation mit Computern
- Der Computer befolgt im Gegensatz zu Menschen oder Tieren Aufforderungen exakt
- Beispiel Berechnung von Fakultät in C: https://www.youtube.com/watch?v=X9BOuShRLEo
Wie interagiere ich mit einem Computer?
- Aufforderungen kann man nur über ein Terminal geben
- Plaintext
- nur mit Tastatur bedienbar
Plaintext
Text ohne Formatierun
Dateien
- Daten werden in Dateien gespeicher
- für Mensch als Text lesbar
- Computer speichert nur Sequenz aus ganz vielen "1" und "0"
- Programme interpretieren diese Sequenz so, dass die Daten für Menschen lesbar sind
- Dateien kann man in Ordnern und Unterordnern speichern
- es gibt einen exakten Pfad
- wichtigste zwei Dateitypen
- Maschinencode
- Die Sprache des Prozessors
- Plaintext
- vom Menschen geschrieben
- "Sourcecode", "Quellcode"
- Maschinencode
- Textdateien bestehen aus Text ohne Formatierung
- Eine Datei ist eine Sammlung logischer Dateneinheiten
- Dateisysteme speichern z.B. Daten, Code, Programme, etc. dauerhaft in Dateien
- Dateisysteme ermöglichen
- Abstraktion von Hintergrundspeichern, z.B. Platten, CD-ROM, USB, Bandlaufwerke, …
- Einheitliche Schnittstelle
Dateiattribute
- Name: Symbolischer Name, vom Benutzer lesbar und interpretierbar
- Größe: Länge der Datei (Bytes, Blocks, ...)
- Zeitstempel: Zeitpunkt der Erstellung, letzte Modifikation, ...
- Rechte: Zugriffsrechte
- Eigentümer: Identifikation
Beispiel:
manfred% ls -l .
…
drwxr-xr-x 10 manfred user 2048 2021-08-21 12:41 progintro
-rw-r--r-- 1 manfred user 1047 2021-09-16 15:56 hello.c
…
ls -llistet den Inhalt des aktuellen Verzeichnisses auf -> Unix Befehle- drwxr-xr-x 10 manfred user 2048 2021-08-21 12:41 progintro
- d: das erste Zeichen gibt den Typ der Datei an. Eind d bedeutet directory
- rwx für den Besitzer (manfred) bedeutet: Lesen (r), Schreiben (w), Ausführen/Betreten (x) ist erlaubt.
- r-x für die Gruppe (user) bedeutet: Lesen und Ausführen erlaubt, aber kein Schreiben.
- r-x für andere (world) bedeutet ebenfalls: Lesen und Ausführen erlaubt, aber kein Schreiben.
- 10 Anzahl der backlinks
- manfred: Der Besitzer (owner) der Datei bzw. Verzeichnis
- user Die Gruppe, der diese Datei zugeordnet ist
- 2048: Größe der Datei in Bytes
- 2021-08-21 12:41: modification time
Operationen auf Dateien
- Erzeugen (create)
- Schreiben (write)
- Lesen (read)
- Löschen (delete)
- Öffnen/Schließen einer Datei (open/close)
Verzeichnisse
- Ein Verzeichnis ist eine Sammlung von Dateien und Verzeichnissen
- Verzeichnisattribute: Ähnlich wie Dateiattribute:
- Name, Größe, Datum des letzten Updates, Eigentümer, Rechte
Unix Pfadnamen
- !200
- Benannt sind die Verbindungen zwischen Dateien und Verzeichnissen
- Verschiedene Pfade für dieselbe Datei bzw. dasselbe Verzeichnis möglich
- bei windows mit backslash
\statt slash/ - Rückverweise: “..“
- Selbstverweise: “.“
- Verschiedene Pfade für dieselbe Datei bzw. dasselbe Verzeichnis möglich
- Aktuelles Verzeichnis:
- /home/manfred/test/
- /home/manfred/test/.
- /home/manfred/test/../test
- wenn am Anfang
/ist das der absolute Pfad, wenn nicht der relative- absoluter Pfad bedeutet, dass der komplette Baum von der Wurzel ausgehen abgebildet ist
- Formatierte Ausgabe:
fprintf - Aufruf:
fprintf(FILE *stream, fmt, args)fprintf()wie printf jedoch mit Dateien / Streams, d.h. konvertiert und gibt die Parameterargsunter Kontrolle des Formatstringsfmtaufstreamaus
- Beispiele: // fprintf(stdout, ...) entspricht printf
− fprintf(stdout, “Hello world\n“); − fprintf(stdout, “Wert von i: %d\n“, i); − fprintf(stdout, “a(%d)+b(%d) ist: %d\n“, a, b, a+b); ```
Formatierte Eingabe: fscanf
- Aufruf:
fscanf(FILE *stream, fmt, args)fscanf()liest vonstreamund versucht, die Eingabe unter Kontrolle des Formatstringsfmtauf die Parameterargsabzubilden
- Beispiele:
// fscanf(stdin, ...)entspricht scanf− int a, b; fscanf(stdin, “%d %d“, &a, &b); − float x; fscanf(stdin, “%f“, &x); − char a; fscanf(stdin, “%c“, &a);
Öffnen von Dateien: fopen
- Aufruf:
FILE *stream fopen(path, mode)fopen()öffnet die Dateipathim Modusmode
- Beispiele:
FILE *file_pointer_in, *file_pointer_out; // öffnet Datei „datei“ zum Lesen file_pointer_in = fopen(“./datei“, “r“); // öffnet „datei“ zum Schreiben file_pointer_out = fopen(“./datei“, “w“); // öffnet „datei“ zum Schreiben mittels Anhängen am Dateiende file_pointer_out = fopen(“./datei“, “a“); - Wichtig: Immer prüfen, ob fopen erfolgreich war, indem du zum Beispiel
if (fp == NULL)prüfst. Ist esNULL, dann gab es ein Problem beim Öffnen (Datei nicht gefunden, keine Berechtigung, …).
Lesen von Datei – Ausgabe auf stdout
// Konvention: „fp“ kurz für „file_pointer“
FILE *fp = fopen(“datei.txt“, “r“);
int a, b;
if (fp == NULL ) {
perror(“Fehler beim öffnen der Datei“);
return 1; }
while (fscanf(fp, “%d %d\n“, &a, &b) != EOF) {
printf(“%d %d\n“, a, b); }
fclose(fp);
- void perror(msg)
- gibt letzte Systemfehlermeldung auf
stderraus
- gibt letzte Systemfehlermeldung auf
Lesen von Datei – Ausgabe von Datei
FILE *fpin = fopen(“datei_in“, „r“);
FILE *fpout = fopen(“datei_out“, „a“);
int a, b;
while (fscanf(fpin, “%d %d\n“, &a, &b) != EOF) {
fprintf(fpout, “%d + %d = %d\n“, a,b,a+b);
}
fclose(fpin); fclose(fpout);
- Hinweis: Fehlerbehandlung fehlt, ist aber notwendig!!!
- Problem: Fehlerhafte Eingabedaten
- Eingabedaten entsprechen nicht unbedingt den Erwartungen
- Z.B. anstelle einer Zahl ein String
- Deshalb immer überprüfen, ob das Lesen erfolgreich war!
- Kann bei scanf, fscanf problematisch sein. Lösung:
- fgets zum Lesen einer Zeile
- gefolgt von sscanf zum Konvertieren des Strings in Token (int, float, etc.)
Formatierte Eingabe: fgets & sscanf
- Aufruf:
char *fgets(char *buf, int n, FILE *stream) fgets()liest bis zum ersten Newline „\n“ vonstream- dabei aber maximal n-1 Zeichen, und fügt „\0“ am Ende hinzu oder
- bis EOF
- je nachdem welche Bedingung als erste zutrifft
char buf[200];
int a, b;
char *h = fgets(buf, 200, stdin); // Liest bis zu 199 Zeichen + '\0'
if (h==NULL) {
printf(„error in fgets“);
exit(1);
}
int ret = sscanf(buf, „%d %d“, &a, &b);
if (ret == 2) {
printf(„read 2 integers: %d %d\n“, a, b);
} else {
fprintf(stderr, „error reading 2 integers\n“);
}
- Finger weg von
gets(char *buf)!!! gets liest unabhängig von der Größe des Buffers bis zum ersten Newline „\n“ von stream. Gefahr eines “Buffer Overflow“ !!!- Sicherheitslücke, weil man so auf den kompletten Speicher zugreifen kann
Programmiersprache
- Eine Programmiersprache ist eine erfundene Sprache, die auf Syntax und Semantik basiert
- legt wohlgeformte Ausdrücke einer Programmiersprache fest
- eine Menge von wohlgeformten Ausdrücken bildet ein Programm
- die Menge aller möglichen wohlgeformten Ausdrücke bildet eine Programmiersprache
- Definiert die Bedeutung von wohlgeformten Ausrücken fest
- gibt an wie Programme zu interpretieren sind
- Ist das Wörterbuch einer Programmiersprache
syntaktisch falsche Programme haben keine Bedeutung
Syntax vs Semantik
- Syntax legt fest, welche Zeichenketten Teil einer Sprache sind
- Semantik legt fest, was Wörter und Sätze bedeuten
- Beispiel
- Syntax: a + b
- Bedeutung: Addition von a und b
Programmiersprachen
Hilfe bei Computerproblem
- Was will ich erreichen?
- Was habe ich getan?
- Was habe ich erwartet?
- Was ist tatsächlich passiert?
Warum C?
- C ist klein und einfach
- für praktische Zwecke entworfen
- C ist Sprache für systemnahe Programmierung
- extrem weit verbreitet bzw. etabliert
- C-Syntax ist Grundlage für viele weitere Programmiersprachen
- Grundlage für viele Vorlesungen
- C ist sehr schnell im Vergleich zu andere Programmiersprachen wie z.B. Python
Compiler
- hello.c ist menschenlesbar (Plaintext)
- hello.o ist maschinenlesbar aber nicht menschenlesbar
- Compiler ist ein Programm
- clang ist ein compiler
Beispiel für compiler
unix> clang -Wall -std=c11 -o hello hello.c
unix> ist der Promt, der zeigt, dass man in einem unix Terminal arbeitet
glang ist das Programm, dass den darauf folgenden Text interpretiert. An dieser Stelle ist der Befehl/Kommando
-Wall -std=c11 -o hello sind alles Optionen/Flag
-
Benennen der Ausgabedatei: Compilerflag –o < name > (Ansonsten wird die Datei a.out generiert)
-
Wir benutzen den Programmierstandard C11 (Compilerflag: -std=c11)
-
-Wall dient dazu, dass beim kompilieren gegebenenfalls Warnungen gegeben werden
Algorithmus
Ein Algorithmus ist eine eindeutige Handlungsanweisung zur Lösung eines Problems. Dabei wird eine bestimmte Eingabe in eine bestimmte Ausgabe überführt. Ein Algorithmus wird in Pseudocode aufgeschrieben
- wichtige Aspekte eine Algorithmus
- Korrektheit
- Macht der Algorithmus was er tun soll
- Effizient
- funktioniert der Algorithmus immer effizient
- egal mit welchen und wieviel Daten
- Terminierung
- hat der Algorithmus ein Ende
- wenn nicht läuft das Programm unbegrenzt weiter, was zu folge hat, dass es eine Endlosschleife gibt
- hat der Algorithmus ein Ende
- Korrektheit
Begriff
- Herkunft des Begriffs des Algorithmus
- 780 - 850 Abu Dscha'far Muhammad ibn Musa al-Chwarizmi
- “Dixit Algorizmi” = “also sprach al-Chwarizmi”
- als Gütezeichen einer Rechnung (ab ca. 1200)
Algorithmus vs. Programm
- Algorithmen beschreiben in prinzipiellen Elementen, was ein Computer ausführen soll
- Programmiersprachen stellen eine Schnittstelle dar, um Algorithmen auf einem Computer definieren und ausführen zu können
- Algorithmen fokussieren auf Korrektheit, Vollständigkeit, und Komplexität
- Programmiersprachen müssen zusätzlich alle Details des Computers berücksichtigen
Beispiel Algorhitmus
Zweierpotenzen in natürlicher Sprache
Berechne die Zweierpotenzen bis n (also solange “2 m < n” gilt):
Sei m gleich 0
Sei p gleich 1
Solange p kleiner n ist, mache:
Gib „2 hoch m ist p“ auf der Konsole aus
Addiere zu m den Wert 1
Multipliziere p mit dem Wert 2
Zweierpotenzen in Pseudocode
m = 0
p = 1
while ( p < n)
Ausgabe "2^m ist p";
m = m +1;
p = p * 2;
Erklärung Zweierpotenz
- m und p sind Variablen, denen ein Wert zugewiesen wird (Zeile 1 & 2)
- while sagt aus, dass der Block wiederholt wird solange die Bedingung p < n erfüllt ist
- In Zeile 5 und 6 werden die Variablen neu zugewiesen. Dafür findet auf der rechten Seite eine Berechnung statt
Zweierpotenz in C
#include <stdio.c>
int main() {
int m = 0;
int p = 1;
int n = 10; //nur Beispiel
while (p < n) {
printf("2^%d ist %d", m, p);
m = m + 1;
p = p * 2;
}
}
Variable
Variablen erlauben es Daten strukturiert zu speichern. Um eine Variable einzubringen muss man sie erst deklarieren, d.h., dass man ihr einen Typen wie int oder char geben muss. Dann kann man der Variable einen "Wert" zuweisen bzw. die Variable initialisieren.
Initialisieren
- Variablen können frei gewählt werden mit folgenden Einschränkungen
- Erste Zeichen: a-z, A-Z, _
- weitere Zeichen: 0-9, a-z, A-Z, _
- keine Schlüsselbegriffe wie z.B. int, while, for, if, ...
Typen von Variablen
Typen definieren
- Art der Werte
- int
- int
- Wertebereich
- int
- wird standardmäßig vom Speicherplatz festgelegt
- int
- 1 Byte = 8 Bit
- Typ legt fest, was das Bitmuster bedeuten soll
- Operationen, die auf den Werten ausgeführt werden können
- z.B. +, -, * , /, %, etc.
Expliziter Typ:
- unit8_t
- u: Unsigned
- int: Integer
- 8: 8 Bit = 1 Byte Speicherplatz
- _ t: "Ich bin ein Typ" (Schreibkonvention)
• uint8_t i = 17; // gültige Operation • uint8_t i = -100; // ungültige Operation
sizeof gibt Größe eines Typs in in Byte aus
- int muss min. dasselbe wie int16_t darstellen, darf aber auch mehr darstellen
- deshalb kann man bei int nicht davon ausgehen, dass es auf jedem anderen System auch funktioniert. Deshalb verwendet man expliziete Typen
einfache Typen
- int: Ganze Zahl ("integer")
- Erlaubt das Speichern eines Integer (ganzahligen Wertes in einer Variable)
- typischerweise 32 Bit
- Wertebereich: -2.147.483.648 (
- char: Zeichen ("character")
- Erlaubt das Speichern eines Zeichens
- Typischer Weise: 8 Bit
- "Wertebereich": -128 bis 127
- a = 97
- boolean: Wahrheitswerte
- float: Gleitkommazahlen
- hat meist 32 Bit -> nicht alle reelle Zahlen darstellbar
- geeignet, wenn kleine Rundungsfehler akzeptabler sind
- enum: Aufzählungen
- Nicht alles lässt sich mit Zahlen gut darstellen
- z.B. Ampel: Rot, Gelb, Grün
- -> Enumerations ("enums") erlauben es eigene Typen als Liste von möglichen Werten („variants“) zu definieren
- Beispiel:
enum TrafficLightColor { Red, Yellow, Green };- Datentyp heißt nun: enum TrafficLightColor und nicht nur TrafficLightColor
- typedef: man kann hiermit Typ umbenennen, damit er vereinfacht wird
- mit einem Unterstrich hinter einem enum deutet man an, dass später im Programm eine Vereinfachung stattfindet -> Schreibkonvention
enum CoinFace_ { Heads, Tails }; typedef enum CoinFace_ CoinFace; CoinFace x = Heads; // äquivalent zu `enum CoinFace_ x = Heads;` //Kompaktere Syntax: typedef enum CoinFace_ { Heads, Tails } CoinFace;
strukturierte Typen
- struct: Strukturierte Datentypen
- Point3d als Beispiel für x-, y- und z-Koordinaten eines Punktes
struct Point3d { float x; float y; float z; }; //erstellt neunen Typ namens `struct Point3d` - So kann man einen Punkt dann initialisieren und implementieren:
// Wert erstellen struct Point3d my_point = { .x = 1,5, .y = 2, .z = -3 }; float a = 5.0 + my_point.y; // Felder zuweisen my_pioint.z = 1; // Felder zuweisen - struct-Werte können genauso kopiert werden wie andere Werte auch
- Funktionen können mit structs arbeiten
- struct in einer struct
- rekursive struct sind nicht möglich!
- Point3d als Beispiel für x-, y- und z-Koordinaten eines Punktes
Wahrheitswerte
- in C ist alles, was Null ergibt falsch und alles andere richtig
- der Programmiersprachenübergreigenden Typ "Boolean" hat nur der Werte "true" und "false"
- boolean ist eindeutiger
Pointertypen
int x = 5; // declare x as an integer variable
int *p, *q; // declare p and q as pointers to an integer
// int* p; and int * p; are OK as well
p = &x; // store address of x in p
int y = *p; // assign y the value p points to, i.e., x, i.e., 5
q = p; // q points to the same location as p, i.e., x
printf(“Value of x: %d (at address %p)”, *p, q);
Arbeiten mit Pointern
- Pointer und struct
- Parameterübergabe an Funktionen
- Call by Value
- Parameterübergabe als Wert
- Werte der Variablen werden übergeben
- Werte der Variablen stehen als lokale Kopie zur Verfügung
- Damit sind Änderungen nur innerhalb der Funktion sichtbar
- Call by Reference
- Parameterübergabe als Adresse
- Adressen der Variablen werden übergeben
- Adresse steht damit lokal zur verfügung und der Zugriff auf den Speicherort ist möglich
- Damit sind Änderungen über die Funktion hinaus sichtbar
- Call by Value
Zuweisungen
- Operator: =
- = ist kein Gleichheitszeichen
- == ist Gleichheitszeichen
- Beispiel
int x, y;
x = 10;
y = -x;
x = y;
- auf der linken Seite Speicherung
- auf der rechten Seite Auswertung
Ausdrücke
- elementare funktionale Einheit
- durch Auswerten entstehen neue Werte
- Ausdrücke werden durch Einsetzen der aktuellen Werte ausgewertet
int celsius;
int fahrenheit = 92;
celsius = (fahrenheit -32) * 5 / 9;
Schleifen
- In Situationen, in welchen ein Programmstück mehrmals durchlaufen soll, wobei sich die Werte ändern verwendet man Schleifen
- Man kann Schleifen in Schleifen tun
while-Schleife
- Anzahl der Iterationen wird durch Bedingung bestimmt
- Wann while benutzen?
- Man will etwas mehrmals machen, aber es ist nicht im voraus klar, wie of
Beispiel
while ( i <= 10) {}
Allgemeine Form
<while-statement> :=
while (<condition>) <block>;
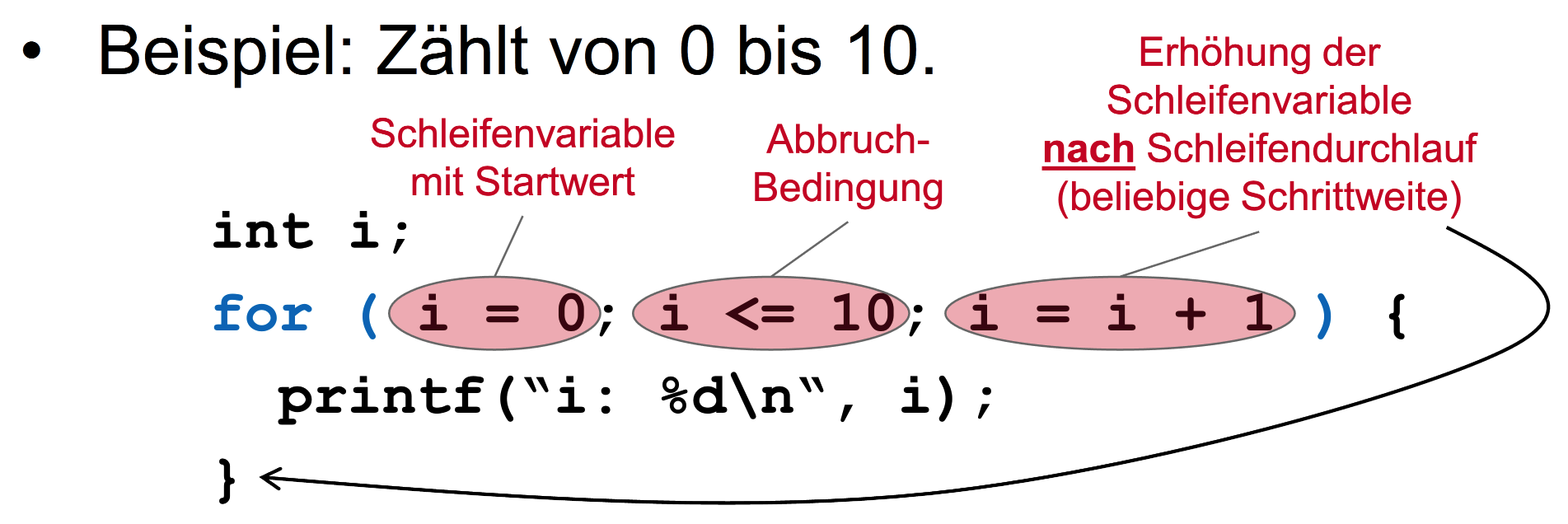
for-Schleife
- Anzahl der Iterationen ist bekannt
- Wann for benutzen?
- Man weiß, wie oft man etwas machen will
Ablauf
- Initialisierung: Deklaration und Initialisierung der Schleifenvariable
- Bedingung: Logischer Ausdruck, der „wahr“ sein muss. Wird vor jeder Ausführung des Schleifenrumpfs getestet.
- Schleifenrumpf: Anweisung(en), die wiederholt ausgeführt werden, solange die Bedingung den Wert „true“ ergibt.
- Fortschaltung
Beispiel
Allgemeiner Syntax
<for-statement> ::=
for(<for-init>; <condition>; <for-update>)
<block>
<for-init> ::= <statement> <for-update> ::= <statement>
Quellcode kommentieren
- Lesbarkeit für andere und einen selbst
- Deshalb immer kommentieren
- sollen übersichtlich und korrekt formatiert sein
- sofort beim Programmieren kommentieren
- jede Funktion kommentieren
- exakte Beschreibung was der jeweile Abschnitt tun soll
/* Kommentar
über mehrere Zeilen
*/
//Kommentar bis Zeilenende
Debugging
- "entwanzen"
- kommt daher, dass die ersten Computer Relais verwendeten. Als eine Wanze ein Relais blockierte, musste man den Computer entwanzen. Deshalb der Name
- Heute spricht man von einem Bug, wenn ein Programm-Fehler vorliegt
- Debugging = Fehlersuche- und Behebung
- Compiler gibt Hinweise auf syntaktische/semantische Fehler
- Programm hält mit Laufzeit Fehler (Run-time Error)
- Programm hält nie an
- Programm läuft vollständig, aber gibt inkorrekte Resultate
- Programm läuft vollständig, aber gibt manchmal(?) inkorrekte Resultate
- Debugging ist Notwendig
- , wenn der Code nicht Compiliert
- , wenn Software "sich anders verhält als erwartet"
- während der Entwicklung
- Code sollte Stück für Stück entwickelt, getestet und debuggt werden
1. Fehlerlokalisierung
- Bug: Codesegment mit nicht beabsichtigten Aktionen.
- Man muss nachvollziehen:
- Was das Programm machen sollte
- Was das Programm wirklich macht
- Problem: Zu viel Informationen!
- Lösung: Einkreisen des Problems!
mögliche falsche annahmen
- Binärcode entspricht Quellcode
- Code, der eine Funktion aufruft, bekommt niemals unerwartete Argumente
- Library-Funktionen funktionieren immer ohne Fehler
- malloc wird immer den angeforderten Speicher geben
- Systembibliotheken und -tools sind fehlerfrei
Suchstrategie
- man sollte zuerst bei besonders verdächtigen Datensturkturen nachschauen
- nach initialisierung
- Nach der ersten, zweiten, mittleren Iteration einer Schleife
- Nach einem Tastendruck, der ein interaktives Programm zum Absturz bringt
- Nach dem Punkt, an dem das Programm die letzte korrekte Ausgabe geliefert hat
- Am Ende von Programm
2. Verstehen des Fehlers
- Was ist der Zustand des Programms vor Ausführung von fehlerhaften Code?
- Was ist der Zustand nach Ausführung des Codes?
- Was ist der erwartete Zustand?
Namen und Werte aller aktiven Variablen
- mit
printf()kann man sich alle "suspekten" Variablen ausgeben lassen
Debugger
- ein Debugger kann Programm an einem bestimmten Punkt unterbrechen
- kann bei Unterbrechung den Zustand des Programms anzeigen
- ein Debugger ermöglicht, den Zustand von Programmen, die durch Laufzeitfehler abgestürzt sind, anzuzeigen
- Führt oft leichter zu dem Punkt, wo der Fehler aufgetreten ist
(Zoltan Somogyi, Melbourne University)
- Before you can fix it, you must be able to break it (consistently)
- Nicht reproduzierbare Bugs ... Heisenbugs ... sind schwierig
- If you can‘t find a bug where you‘re looking, you‘re looking in the wrong place
- Eine Pause machen und später weitermachen, ist im Allgemeinen eine gute Idee
- It takes two people to find a subtle bug, but only one of them needs to know the program
- Die zweite Person stellt Fragen, um die Annahmen des Debuggers in Frage zu stellen
Workflow
- wenn man Idee hat, wo der Bug ist
- breakpoint kurz vorher setzen
- Ab dann in Einzelschritten fortfahren
- Nun sollte man sehen, welche Variablen einen unerwarteten Wert annehmen
- wenn man weiß, welche Variable den falschen Wert hat, muss man nach dem Warum fragen
- zwei Möglichkeiten
- Bei der Zuweisung von der Variable ist das Statement falsch
- Werte anderer Variablen in diesem statement sind falsch
- zwei Möglichkeiten
- man kann auch eine Hypothese aufstellen:
Kommandozeilen-basierte Debugger
- erlauben kontrollierte Programmausführung
- ermögliche Anzeige des Zustands des Programmes
- ermöglichen Änderung von Variablen
gdbundlldbsind Debugger für C
gdb
- kompilieren mit
-g - Aufruf ohne core files:
-gdb prog
- Aufruf mit corefiles
-gdb prog core
Befehle
quit– verlässt gdbhelp [CMD]– on-line Hilfe für Kommando CMDrun ARGS– Ausführen des Programms mit Argumenten ARGS- z.B. aus dem Befehl ./prog arg1 arg2 wird im Debugger run arg1 arg2
break [PROC|LINE]– Setzen eines Haltepunks (breakpoint). Wenn das Programm die Funktion PROC (oder die Linie LINE) erhält, wird die Ausführung des Programms unterbrochen und die Kontrolle an gdb übergebennext– single step (over procedures): Ausführen des nächsten Statements. Falls das Statement ein Funktionsaufruf ist, ausführen des gesamten Funktionskörpersstep– single step (into procedures): Ausführen des nächsten Statements. Falls das Statement ein Funktionsaufruf ist, halte beim ersten Statement in der Funktionbt/backtrace– gibt Aufrufkette (Stack-trace) aus- Mit core dump: Finden, welche Funktion das Programm ausgeführt hat, als es abgestürzt ist
- Bei Unterbrechung: Ausgabe der Aufrufkette
up [N]– Wechseln des Kontexts eine Ebene höher im Stack; ändert den Rahmen (Scope) einer bestimmten Funktion im Stackdown [N]– Wechseln des Kontexts eine Ebene niedriger im Stacklist [LINE/PROC]– Anzeigen des Programmcodes; zeigt 5 Zeilen Code vor und nach dem momentanen Statementprint EXPR– Zeigt die Werte der Expression EXPR
Fehler Speicherverwaltung
- Memory Leaks
- Uninitialisierter Speicher
- Use after free
- Das tool valgrind kann Speicherfehler auffinden
Memory Leaks
- Speicher wird angefordert, aber nicht freigegeben
- Fatal bei lang laufenden Prozessen
- valgrind:
--leak-check=full
Uninitialisierter Speicher
- Speicher wird gelesen, ohne dass vorher geschrieben wurde
- Fehler treten oft unerwartet auf, unabhängig vom Speicherinhalt
- Kann Informationen preisgeben (z.B. Crypto-Schlüssel)
- valgrind:
--undef-value-errores=yes--malloc-fill=0xfe
Use after free
- Speicher wird gelesen, nachdem er freigegeben wurde
- Fehler treten dann auf, wenn der Speicher neu vergeben wird
- valgrind:
track-origins=yes
Fehlertypen
Syntaxfehler
- ein Fehler führt dazu, dass das ganze Programm nicht (wie gewollt) funktioniert
Semantikfehler
- wenn kein Fehlercode aber nicht erwartetes Ergebnis -> Semantikfehler
- schwerer zu finden als Syntaxfehler weil keine Fehlermeldung
Block
- ein Block ist der Code, der sich zwischen zwei geschweifte Klammern befindet.
- Ein Block öffnet einen Scope („Sichtbarkeit“). Innerhalb eines Scopes, ist alles von „außerhalb“ sichtbar. Von „außen“ kann nicht in einen Scope „hineingeblickt“ werden.

Bedingte Anweisung
Bedingte Anweisung ohne Alternative
- mit if durchführbar
- wenn x kleiner 0 gilt, dann weise x den neuen Wert -x zu. So bestimmt man den Absolutbetrag von x aus
if (x < 0) {
x = -x
}
- syntaktische Form:
if (<condition>) <block>
Bedingte Anweisung ohne Alternative
if (n == 1) {
// do something
} else
{
// do something else
}
- syntaktische Schreibweise
if (<condition>) <block> else <block>
Boolean Expressions
- Logische Ausdrücke
- Wert == 0 -> false/falsch
- Wert != 0 -> true/wahr
- Verknüpfung von logischen Ausdrücken
- && logisches und (beides wahr)
- || logiesches oder
Funktion
- Bilden Grundgerüst von jedem Programm
- jede Funktion kann von jeder Funktion aufgerufen werden
- Warum
- Einfachheit: Funktion nur einmal korrekt implementieren; funktioniert dann immer gleich.
- Wartbarkeit: Änderung nötig? Nur eine Stelle (die Funktion) muss angepasst werden.
- Funktion kann sich selbst aufrufen -> Rekursion
Definition
// function to calculate the maximum of a and b
int max (int a, int b) {
if (a > b) {
return a; // a is max
} else {
return b; // b is max
}
}
Aufruf
int main() {
int n = 10;
int m = 11
printf("max of n, m: %d\n", max(n, m));
}
Rekursion
Die Funktion ruft sich selbst auf
- Es muss unbedingt eine Terminierung stattfinden, weil man sonst ein Endlosprogramm erstellt
- Nie Abbruchbedingung vergessen
- Man braucht bei einer Rekursion zwangsweise einen "Fortschritt", sonst Endlosprogramm trotz Terminierung


- Viele mathematische Funktionen sind einfach rekursiv definierbar.
- z.B.
- z.B.
Schleife vs. Rekursion
float potenz(float x, int n) {
float sum = 1;
while (n--) sum *= x;
return sum;
}
potenz :: Double -> Int -> Double
potenz x n = if n == 0 then 1 -- Rekursionsanker
else x * (potenz x (n - 1))
```
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/modularisierung/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Modularisierung
- Funktionen können in verschiedene Module (Dateien) getrennt werden
- Warum?
- Übersichtlichkeit
- Erweiterbarkeit
- Wiederverwendbarkeit
- Wartbarkeit
- bisher haben wir alle Funktionen vor main() implementiert
- Man kann eine Funktion wie folgt auslagern
1. header Datei erstellen mit Definition der Funktion (Dateiendung .h)
2. c Dokument erstellen dort Funktion Funktion implementieren (Dateiendung .c)
3. Am Anfang vom Programm: **#include "headerdateiname.h"**
## Beispiel
![[Tag4-Donnerstag-Programmierkurs.pdf#page=58]]
-
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/speicher/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Speicher
>[!Kernkonzept]
>Speicher besteht aus einer Folge von Bytes
## Variablen im Speicher
- Beispiel *int32_t*: wird in 4 aufeinanderfolgenden Bytes gespeichert
- Deklaration einer Variable reseriert Speicher für sie
- 
- Die Variablen werden nicht unbedingt hintereinander abgelegt
- Zuweisung entspricht Belegung des Speichers mit einem Wert
## Speicher - Abstraktion
- Virtueller Speicher: Ein Bytarray
- .png)
- Aus Sicht eines Programmes:
- Jedes Programm hat seinen eigenen Speicher
- Es hat eine "unbegrenzte Speichermenge"
- Der Zugriff auf alle Speicherbereiche ist gleich schnell...
## Speicher - Realität
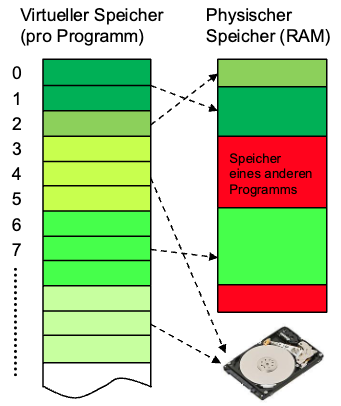
- kein unbegrenzter physikalischer Speicher
- Alle Programme teilen sich den selben Speicher
- Speicherplatz wird das Betriebssystem zugewiesen und verwaltet
- Es gibt eine Speicherhierachie
- Cache, RAM, Festplatte, Netzwerk-Speicher (schnell -> langsam)
- Speicherzugriffsfehler sind besonders schwer zu finden
- Effekte sind oft weit von der Ursache entfernt
## Speicher und C-Programme
### implizit
- Speicher nach Bedarf für
- Variablen
- Arrays
- Funktionen
- Problematik
- Speicher für C-Funktionen unbekannt vor Programmaufruf
- Warum? Funktionsaufrufreihenfolge unbekannt!
- Idee: Speichern der Variablen, etc. in einer dynamisch wachsenden Datenstruktur: User-Stack (Benutzer-Stapel)
### explizit
- Speicher bei Bedarf explizit für C-Variablen, wenn die benötigte Speicher von Parametern abhängig ist
- Problematik
- Speicherbedarf für C-Variablen unbekannt vor Programaufruf
- Warum? Anforderungen (Parameter) unbekannt!
- Idee: Speichern der Variablen, etc. in einer weiteren dynamisch wachsenden Datenstruktur: dem Heap (Haufen)
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/hexadezimal/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Hexadezimal
- 1 Byte = 8 Bit ⇒ kann 28 verschiedene Werte darstellen
- $2^8$ Werte = [0, 255] (00000000 – 1111111111)
- Zusammenfassung von 4 Bit zu einer Ziffer (0 – „15“)
- Ziffern: 0, …, 9, A, B, C, D, E, F
- D.h. Zahlensystem zur Basis 16 („hexadezimal“)
- 2 hexadezimale Zahlen können 1 Byte darstellen:
00000000 – 11111111 (binär)
0 – 255 (dezimal)
00 – FF (hexadezimal)
- Kennzeichnung: „0x“ vorangestellt, z.B. 0x7edf04ec
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/speicheradresse/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Speicheradresse
- Der Ort an dem die Daten tatsächlich gespeichert sind
- kann sich ändern
- Zugriff auf die Adresse mittels ***&*** vor dem Variablennamen
- Speicheradressen "zeigen" an eine Stelle im Speicher $\implies$ "Zeiger" bzw. "Pointer"
- Beispiel
```c
int x = 4;
printf ("Es gilt x = %d, und x hat die Speicheradresse %p", x, &x);
```
- Speicheradresse ist Hexadezimal abgespeichert
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/hexadezimal/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Hexadezimal
- 1 Byte = 8 Bit ⇒ kann 28 verschiedene Werte darstellen
- $2^8$ Werte = [0, 255] (00000000 – 1111111111)
- Zusammenfassung von 4 Bit zu einer Ziffer (0 – „15“)
- Ziffern: 0, …, 9, A, B, C, D, E, F
- D.h. Zahlensystem zur Basis 16 („hexadezimal“)
- 2 hexadezimale Zahlen können 1 Byte darstellen:
00000000 – 11111111 (binär)
0 – 255 (dezimal)
00 – FF (hexadezimal)
- Kennzeichnung: „0x“ vorangestellt, z.B. 0x7edf04ec
</div></div>
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/array/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Array
>[!Kernkonzept]
>- Ein Array ist eine Liste von Daten gleichen Typs
>- Hat eine feste Länge
>- Wir dim Speicher hintereinander abgelegt

- Warum Arrays?
- Variablen sind perfekt für einzelne Elemente bringen aber Probleme und Einschrnkungen mit sich:
- mehrere Elemente des gleichen Typs
- Darstellung: a1, a2, a3, a5, ..., a10
- viel zu viel Schreibarbeit
- keine Möglichkeit der Iteration
- keine Strukturierung
- Arrays und Pointer
- Arrayvariablen sind Pointer
- Der Inhalt der ArrayVariablen ist die Adresse des ersten Elements des Arrays
- Arrays vs. Pointer
- `p = data` ist äquivalent zu `p = &data[0]`
- Zugriff auf Array-Elemente
```c
int32_t data[10]; // int32_t = 4 Bytes => 40 Bytes
int32_t* p = data; // p points to array
int32_t* q;
*p = 2;
q = p + 1; // “+ 1“ means:
// “+ (1 * element size)“ => + 4 Bytes
*q = 3;
*(p + 2) = 5; // + 2 elements !!!
```
- Mit Index einfacher
- Zugriff auf Arrayelemente mit Index in [ ]
- Erstes Element hat den Index "0", d.h. [0] !
```c
int32_t data[10];
data[2] = 6; // Zugriff in
data[0] = 5; // beliebiger
data[1] = 4; // Reihenfolge
```
- Initialisierung von Arrays
```c
// Deklaration Array mit Speicherplatz für 5 Integer
int32_t a[5];
/* Deklaration mit Initialisierung Array mit Speicher für 5 Integer */
int32_t arr[] = { 1, 8, 7, -1, 2 };
```
- man kann alles Arrayelemente mit einer for-Schleife durchlaufen
- es gibt mehrdimensionale Arrays: `int32_t mat[3][2] = { {00, 01}, {10, 11}, {20, 21} };`
- zweidimensionale Array visualisiert:
![[Tag7-Dienstag-Programmierkurs.pdf#page=46]]
- Ein Array reserviert den vorgegebenen Speicherplatz automatisch
- **ACHTUNG:** Es wird nicht überprüft, ob `index` innerhalb des reservierten Speicherplatzes liegt -> andere Speicher kann ausgelesen oder überschrieben werden
- **Call-by-Value** gibt es bei Arrays nicht
# Probleme:
- Die Anzahl der Elemente ist oft vorher nicht bekannt
- Die Anzahl ändert sich während des Programmdurchlaufs
- Löschen: Lücken im Array
- alle weiteren Elemente müssen verschoben werden
- Einfügen: Neues Array und Daten müssen hineinkopiert werden
- Größe wird bei der initialisierung festgelegt -> nicht änderbar
- …
- Folgerung:
- Brauchen dynamischere Möglichkeit der Speicherverwaltung
- Möglichkeiten: − Ad hoc mittels malloc / realloc
- Oder mittels dynamischer Datenstrukturen
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/dynamische-speicherallokation/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Dynamische Speicherallokation
>[!Prinzip]
>Zuteilung von Speicher nach Bedarf, da begrenzte Ressouce
- implizit, wenn benötigte Menge Speicher zur Compilerzeit feststeht
- z.B. Variable
- explizit, wenn benötigte Menge Speicher zur Compilerzeit unbekannt ist
- z.B. Array mit unbekannter Länge
## **malloc:** ***M**emory **ALLOC**ation* in C
- Dynamische Speicherverwaltung
```c
#include <stdlib.h>
void* malloc(size_t size)
```
- Es wird ein Speicherblock mit der Größe `size` Bytes reserviert
- Rückgabe: Zeiger auf Speicherblock der wenigsten Größe `size` Bytes hat
- Speicher wird nicht (mit 0) initialisiert
- ***void**** : Ein Pointer auf einen nicht festgelegten Typ
### Fehlerbehandlung in C mit `malloc`
- wenn `malloc` keinen Speicherplatz reservieren konnte, weil der gesamte Speicher bereits verwendet wird, dann wird als Ergebnis in spezieller Pointer-Wert `Null` ausgegeben
```c
int8_t *foo_with_error_handling(int32_t n){ // to be used
int8_t *p;
// allocate a block of n bytes p
= (int8_t *) malloc(n);
if (p == NULL){
perror("malloc failed while allocating n bytes");
exit(1);
}
return p;
}
Fehlerbehandlung in C
Motivation:
- In Jeder Funktionen können Fehler auftreten
- wie werden diese an die aufrufende Funktion zurückgemeldet, um dann behandelt zu werden?
- z.B. Speicher ist endlich -
mallocist nicht in der Lage, die gewünschte Speichermenge zu allokieren
1. Methode: Nutzen von Rückgabewerden
- Falls Fehler in Funktion auftritt:
- expliziter Wert wird zurückgegeben
- Fehlercode in globaler Variable errno setzen
- Setzen einer Hilfsfunktion perror. So kannn die Konsole eine Fehlermeldung ausgeben
- Es gibt Fehler, die sollen zum Abbruch führen
2. Methode: Nutzen der Abbruchfunktion int exit()
- Falls ein Fehler in einer Unterfunktion auftritt:
- Erst Fehleranalyse
- Dann Abbruch des Programms mittels
exit()- Rückgabewert > 0
- z.B:
exit(1);
- Rückgabewert > 0
exitbricht das Programm vollständig ab- Erfolgreiche Ausführung eines Programms gibt den Wert 0 zurück
Syntaktische Fehler beheben
- zum ersten Fehler gehen
- in die entsprechende Zeile Code gehen (siehe Fehlermeldung Compiler)
- Fehler verstehen
- Fehler beheben
- Kompilieren
- Fehler behoben?
- wenn ja: nächsten Fehler beheben
- wenn nein: zurück zu Schritt 3
Strings
- Strings sind im Prinzip Arrays aber die Werte sind
char(character) anstattint - wird im Speicherplatz durch
\0terminiert - Speichergröße ist Länge des
stringin Byte (ein Zeichen = Ein Byte) + 1 Byte
- Strings haben im Gegensatz zu Arrays keine feste Länge
Programm zum berechnen der Länge eines String
#include <stddef.h>
#include <stdio.h>
int strlen (char *s) {
int l = 0 //Stinglänge mit 0 initialisieren
if (s == 0) return -1;
while (*S != \0) {
l++;
i++;
}
return l;
}
mit Standard-Header-Datei <string.h> kann man diese Funktion einfach einbinden in jedes Programm in C. Das sieht dann wie folgt aus:
#include <string.h>
int strlen (char *s) // liefert Länge von *s ohne das \0
Ausgabe mittel printf
- Formatierte Aufgabe:
printfprintf()gibt die Parameter unter "Steuerung" des Formatstrings fmt auf stdout aus- Aufruf:
int printf(char fmt, ...) - fmt: Formatstring (Zeichenkette)
- Die weiteren Parameter müssen den Typ haben, wie er in
fmtangegeben ist
- Aufruf:
printf(): Formatzeichen in C
| Platzhalter | Datentyp | Beschreibung |
|---|---|---|
%c |
char |
Einzelzeichen |
%d |
int |
Integer |
%f |
float |
Gleitkommazahl |
%p |
void * |
Pointer |
%s |
char * |
Zeichenkette/String |
- Das war die Programmiersprache C.
Ein- und Ausgabekanäle
- Jeder Unix-Prozess hat voreingestellt drei Kanäle für Ein-/Ausgabe
stdinStandardeingabe, meist TastaturstdoutStandardausgabe, meist BildschirmstderrStandardfehlerausgabe, meist Bildschirm
- Standartkanäle sind umlenkbar. Also in Dateien
$ ./meinprog < InFile
$ ./meinprog > OutFile - Man kann mit
|Standartkanäle kombinieren
$ ./meinprog1 | sort > OutFile
./meinprog1als Eingabe fürsortverwenden
Git
- Freie Software zur verteilten Versionsverwaltung von Dateien (Sourcecode)
- Durch Linus Torvals (
- Name: ein Witz von Linus Torvalds
- “I’m an egotistical bastard, and I name all my projects after myself. First ‘Linux’, now ‘Git’.”
- Git (Brit. ugs): Blödmann, Mistkerl
- Warum Versionsverwaltung
- verteilter Zugriff
- Sicherung
- Rückkehr auf alte Versionen möglich
- beschützt vor Fehlern
- Unterschiede zwischen Versionen
- Grafischer Überblick zu Versionsverwaltung
![[Tag9-Donnerstag-Programmierkurs.pdf#page=23]]- ein User kann seinen lokalen Source-Code commiten (
commit) in die lokale Repository - der User kann seine lokale Repository mit
pushin der Remote-Repository speichern- Code wird als Source-Code Version 1 gespeichert
- Ein anderer User kann die neuesten Änderungen aus der Remote-Repository abrufen (
pull) und in seine lokale Repository integrieren. - Ein weiterer User kann die komplette Remote-Repository klonen (
clone) und erhält dadurch eine lokale Kopie der Repository zur eigenen Bearbeitung
- ein User kann seinen lokalen Source-Code commiten (
Pseudocode
Pseudocode ist eine Beschreibungssprache für Algorithmen, die von spezifischen Programmiersprachen losgelöst ist
Pseudocode ignoriert viele Details wie u.A: Variablen-Deklaration, Bibliotheken, ... .
Schreibkonventionen
- Schleifen (for, while, repeat)
- Zuweisungen durch
- Variablen sind lokal definiert
- Keine Typdeklaration, wenn Typ aus dem Kontext klar
- komplexe Datenstrukturen wie Array möglich
- Zugriff auf Array beginnt mit 1 statt mit 0 wie in C
- Blockstruktur durch Einrücken
- Bedingte Verzweigungen (if then else)
- if summe > 9000 then print “over nine thousand“
- Rückgabe von Werten durch return
- Kommentare durch ➢, oder //
- keine ; nötig
insertion sort
- vergleichender Sortieralgorithmus
- stabil
Algorithmus:
Idee Insertion Sort
- Die ersten j -1 Elemente sind Sortiert
- innerhalb eines Schleifendurchlaufs, wird das nächste Element
arr[j]in die bisherige Reihenfolge sortiert eingefügt- überprüfen, ob
arr[j]kleiner ist alsarr[j -1] - wenn ja
- solange wiederholen, bis einsortiert
- Das selbe mit dem nächsten Element
- überprüfen, ob
- Am Ende ist die gesamte Folge sortiert
Effizienz
Sortieralgorithmen
- Eingabe: Folge von n Zahlen (
- Ausgabe: Permutation (
Einfach vergleichende Sortierverfahren
Fortgeschrittene vergleichende Sortierverfahren
Nicht vergleichende Sortierverfahren
bei Arrays geeignet, welche verhältnismäßig viele Werte und einen kleinen Wertebereich haben
Stabilität Sortierverfahren
![[introprog-v02-simple-sort.pdf#page=51]]
selection sort
- vergleichender Sortieralgorithmus
- nicht stabil
Algorithmus:
Idee selection sort
- die ersten j -1 Elemente sortiert (am Anfang alles unsortiert)
- innerhalb eines Schleifendurchlaufs wird das kleinste unsortierte Element mit j vertauscht
- am Ende ist alles Sortiert
Effizienz
- bei steigender Länge des Arrays steigt die Laufzeit quadratisch
- Die Laufzeit ist vom Wertebereich unabhängig
bubble sort
- vergleichender Sortieralgorithmus
- stabil
Algorithmus:
Idee bubble sort
- Die letzten Elemente von j bis n sind sortiert (zu Beginn j= n-1)
- Die größten Elemente steigen auf (bubblen), wie Luftblasen, die zu ihrer richtigen Position aufsteigen
Effizienz
- je unsortierter das Array ist, desto länger dauert es
- invertiert sortiert ist der worst case
- bei steigender Länge des Arrays steigt die Laufzeit quadratisch
- Die Laufzeit ist vom Wertebereich unabhängig
count sort
- sortieren durch zählen der Anzahl des Vorkommens einzelner Werte
- ungeeignet wenn positionstreue wichtig ist, da count sort ein instabiles Sortierverfahren ist
- ungeeignet, wenn großer Wertebereich
- wenn die werte aus einem kleinen Wertebereich stammen ist es wahrscheinlich, dass Werte mehrfach vorkommen
Algorithmus
Idee count sort
- Die grundlegende Idee von count sort ist, dass man die Häufigkeit der Werte zählt, um so das Array von Grund auf neu zu initialisieren
- 1.: Initialisierung Hilfsarray
-
-
- 3.: Berechnung Häufigkeit
-
-
-
- 8.: Schreiben des sortierten Arrays
-
- Veranschaulichung:
![[introprog-v02-simple-sort.pdf#page=67]]
Effizienz
Komplexität
- Die Komplexität einesAlgorithmus hängt von folgenden Faktoren ab:
- Rechenmodell
- Laufzeit
- Raumkomplexität
Laufzeit
Die Laufzeit eines Algorithmus gibt an, wie viel Zeit benötigt wird, um eine Eingabegröße zu verarbeiten, oft in Abhängigkeit von der Größe der Eingabe dargestellt. Sie dient dazu, die Effizienz und Skalierbarkeit von Algorithmen zu bewerten und zu vergleichen.
- Problem bei Laufzeitanalyse ist, dass die tatsächliche Laufzeit von vielen Faktoren abhängt
- Hardware
- Software
- Rechnerarchitektur
- Übersetzer
- Implementierung
-> Laufzeit soll unabhängig von Hard- und Software gelten. D.h. wird in der Regel auf der Basis der von Pseudocode gemacht
- Maschinenmodell - uniform
- Eine Pseudocode-Instruktion braucht einen Zeitschritt
- Wird eine Instruktion r-mal aufgerufen, werden r Zeitschritte benötigt
- Die Zahlengröße spielt keine Rolle
- für Schleifen gibt es Regeln:
- Sequenz: max der Teile.
- Schleife: (max. Iterationszahl) × (Body‑Komplexität).
- Halbierung / Verdopplung: O(log N)
- Geschachtelt: Komplexitäten multiplizieren.
- Danach Konstanten streichen.
- Um die Laufzeit zu analysieren, schauen wir uns die Größenordnung der Laufzeit an. Also das asymptotische Verhalten der Laufzeit als Funktion der Eingabegröße n
- Details werde ignoriert
- Dadurch erhält man Laufzeit- / Wachstumsklassen (logarithmisch, linear, quadratisch, exponentiell, etc.), in die man Algorithmen einordnet.
- Laufzeit eines Algorithmus hängt ab von:
- Größe der Eingabe (Parameter n)
- Art der Eingabe
- Beobachtungen
- insertion sort ist bei aufsteigend sortierten Eingaben schneller
- insertion sort ist bei absteigend sortierten Eingaben langsam
- Die Laufzeit lässt sich als Funktion T(n) darstellen. n ist die Eingabegröße. Ziel ist es die oberen Schranken (Garantien) zu finden
- Obere Schranken:
- Untere Schranken:
- Obere Schranken:
- Da je nach Rechenmodell, also welche Hard- und Software verwendet wird, die tatsächliche Laufzeit stark variieren kann, rechnet man in Schritten
Laufzeitanalyse Beispiel
In diesem Beispiel ist der Wert von sum Äquivalent zu der Anzahl an Schritten, die der Algorithmus durchläuft
Nach der Ausführung hat sum den Wert
Nach der Ausführung hat sum den Wert
Nach der Ausführung hat sum den Wert
Größenordnungen:
| Wachstum | W-Ordnungen | N = 1000 | 10N | 100N | 1000N |
|---|---|---|---|---|---|
| konstant | 1 | 1 Minute | 1 Minute | 1 Minute | 1 Minute |
| logarithmisch | log N | 1 Minute | 1,3 Minuten | 1,6 Minuten | 2 Minuten |
| linear | N | 1 Minute | 10 Minuten | 2 Stunden | 1 Tag |
| leicht überlinear | N log N | 1 Minute | 13 Minuten | 3 Stunden | 1½ Tage |
| quadratisch | N² | 1 Minute | 2 Stunden | 5 Tage | 23 Wochen |
| kubisch | N³ | 1 Minute | 1 Tag | 2 Jahre | 2000 Jahre |
| exponentiell | 2^N | 1 Minute | ∞ | ∞ | ∞ |
Fallunterscheidung
- wie oben steht kann die Laufzeit bei gleichem n stark variieren. Deshalb führt man Fallunterscheidungen durch
Worst-Case Analyse
- Für jedes n definiere Laufzeit
- T(n) = Maximum über alle Eingaben der Größe n
- Garantie für jede Eingabe / „schlechtester Fall“
- Üblich für Laufzeitanalyse
- Beobachtung:
- Betrachte nun Algorithmus A mit Laufzeit 100n und Algorithmus B mit Laufzeit 5n²
- Ist n klein, so ist Algorithmus B schneller
- Ist n groß, so wird das Verhältnis Laufzeit B / Laufzeit A beliebig groß
- Algorithmus B braucht also einen beliebigen Faktor mehr Laufzeit als A (wenn die Eingabe groß genug ist)
- Betrachte nun Algorithmus A mit Laufzeit 100n und Algorithmus B mit Laufzeit 5n²
Average-Case Analyse
- Für jedes n definiere Laufzeit
- T(n) = Durchschnitt über alle Eingaben der Größe n
- Hängt von Definition des Durchschnitts ab (wie sind die Eingaben verteilt)
Best-Case Analyse
- Für jedes n definiere Laufzeit
- T(n) = Minimum über alle Eingaben der Größe n
- „Nicht“ garantiert für jede Eingabe / „bester Fall“
Beispiel: Laufzeitanalyse von insertion sort
Worst-Case
-> konstante Faktoren wenig Aussagekräftig, da hier im Beispiel gezeigt wird, dass bei steigendem n alles von
Asymptotische Laufzeitanalyse
- ignorieren von konstanten Faktoren
- Betrachte das Verhältnis von Laufzeiten für
- Klassifiziere Laufzeiten durch Angabe von „einfachen Vergleichsfunktionen“
O-Notation – Obere Schranke
!250
!250
- Beim Wachstum ignorieren wir konstanten
- Die Theta-Notation beschreibt, dass eine Funktion
- wobei:
- wobei:
Echte obere und untere Schranke
- o-Notation: echte obere Schranke
Interpretation
| "asymptotische Version" | von |
|---|---|
| O | |
| o | |
| Ausdruck | Wachstum von |
Vergleich | Wachstum von |
|---|---|---|---|
| Wachstum von |
Wachstum von |
||
| Wachstum von |
Wachstum von |
||
| Wachstum von |
Wachstum von |
||
| Wachstum von |
Wachstum von |
||
| Wachstum von |
Wachstum von |
Mehrere Parameter & Datenstrukturen:
- Graph‑Durchlauf: äußere Schleife über V Knoten, innere über ausgehende Kanten ⇒
- PriorityQueue.add():
- PriorityQueue.add():
- Amortisierte vs. Worst‑Case Kosten beachten.
Laufzeitklassen
| faktoriell | |
| exponentiell | |
| kubisch | |
| quadratisch (polynomiell) | |
| super-linear | |
| linear | |
| Wurzelfunktion | |
| logarithmisch | |
| beschränkt/konstant |
Hierarchie
!Laufzeitklassen Vergleich.png
Laufzeitanalyse von Sortieralgorithmen
- insertion sort
- Worst-Case:
- Best-Case:
- Worst-Case:
- selection sort
- Worst Case:
- Worst Case:
- bubble sort
- Komplexität:
- Komplexität:
- count sort
- Komplexität:
- n = Länge Array
- m = Wertebereich
- Komplexität:
Laufzeit elementarer Java-Strukturen (worst-case)
| Struktur | Operation | Laufzeit |
|---|---|---|
| Stack (Resizing‑Array) | push, pop | O(1) |
| Queue (Ring‑Array) | enqueue, dequeue | O(1) |
| LinkedList | addFirst, pollFirst | O(1) |
| get(i), set(i), contains | O(N) | |
| PriorityQueue (Heap) | add, removeMin | O(log N) |
| ArrayList / ArrayDeque | addLast | amort. O(1) |
(ArrayDeque meist schnellste Deque; ArrayList Einfügen mittendrin O(N)).
Rekursionsbaum
| Muster | Baumhöhe | Verzweigungen k | Gesamtlaufzeit |
|---|---|---|---|
| T(N)=T(N−1)+c | O(N) | 1 | Θ(N) |
| T(N)=T(N/2)+c | O(log N) | 1 | Θ(log N) |
| T(N)=T(N−1)+T(N−2)+T(N−3)+c | O(N) | 3 | O(3ᴺ) |
| T(N)=2·T(N/2)+c | O(log N) | 2 | Θ(N) |
Komplexitätsklassen
Komplexitätsklassen sind Kategorien, die Berechnungsprobleme danach gruppieren, wie viel Rechenzeit ein Algorithmus im schlimmsten Fall benötigt, um sie zu lösen, abhängig von der Größe der Eingabe.
| Klasse | Definition | Bedeutung |
|---|---|---|
| P | Probleme lösbar in polynomieller Zeit | „praktisch“ effizient |
| NP | Lösung prüfbar in polynomieller Zeit | enthält P |
| NP‑schwer | Jedes NP‑Problem polynomiell reduzierbar | mind. so schwer wie NP |
| NP‑vollständig | in NP und NP‑schwer | härteste NP‑Probleme |
- P =? NP offen (Millennium‑Problem, 1 Mio $).
- Polynomzeit für ein einziges NP‑vollständiges Problem ⇒ P = NP.
Typische NP‑vollständige Probleme
- Traveling‑Salesman (TSP): Finde in einem vollständigen, gewichteten Graphen einen Zyklus mit minimalem Gewicht, der jeden Knoten genau einmal enthält
- Hamilton‑Pfad/‑Zyklus: Finde einen Pfad, der jeden Knoten eines gegebenen Graphen genau einmal besucht.
- Max‑Cut: Bestimme in einem gewichteten Graphen einen Schnitt mit maximalem Gewicht.
- 0/1‑Rucksack, auch bei Beschränkung auf ganzzahlige Gewichte
Raumkomplexität
- Speicherbedarf ist wichtig und ein interessantes Maß
- Häufig jedoch kein sehr selektives Kriterium zur Unterscheidung von Algorithmen
- Der Speicherbedarf unterschiedlicher Algorithmen für dasselbe Problem unterscheidet sich meist nur um einen (geringen) konstanten Faktor.
- Allerdings kann zeitlicher Aufwand durch räumlichen Aufwand ersetzt werden und umgekehrt, z.B.:
- Bei wiederholt auszuführenden identischen Berechnungen kann man das Ergebnis speichern und wiederverwenden
- Der Speicherbedarf wächst häufig mit der Menge der Daten, mehr als quadratisches Wachstum ist selten.
Topographie
Topographie ist ein fundamentales Feld der Geowissenschaften, das die physische Beschaffenheit der Erde detailliert erfasst und darstellt. Sie ist essenziell für Planung, Entwicklung, Umweltmanagement und zahlreiche andere Anwendungsbereiche. Das Kernkonzept sind Höhenunterschiede, was bedeutet, dass man sich das Profil der Erde anschaut und die Verteilung von natürlichen sowie künstlichen Merkmalen analysiert.
Einfache Datenstrukturen
- Einfache Datenstrukturen sind:
Vergleich
| Operation | Static Array | Dynamic Array | linked list |
|---|---|---|---|
| Element Access | O(1) | O(1) | O(n) |
| Insert at begin | O(n) | O(n) | O(1) |
| Insert at end | O(n) | O(1) | O(1)* |
| Insert at known position | O(n) | O(n) | O(1) |
| Extra space | 0 | O(n) | O(n) |
* wenn Zeiger auf Ende zur Verfügung
verkettete Listen
Basics
- Verkette Liste: Elemente bestehen aus Inhalt und Nachfolger.
- Jedes Element “verweist” auf seinen Nachfolger.
- Elemente können an beliebiger Stelle eingefügt und gelöscht werden.
- Dabei wird „nur“ der Verweis auf den Nachfolger umgesetzt.
- Und der Speicher|Speicher]] des gelöschten Elements freigegeben
- Implementierung benötigt
- Elemente bestehend aus
- Inhalt
- Verweis auf Nachfolger
- Und die Logik zum
- Einfügen
- Durchlaufen und Ausgeben
- Löschen
- Elemente bestehend aus
- Listenelemente sind ein zusammengesetzter Datentyp
- Datenwert
- Verweis auf das nächste Element
- Wurzel
- Erstes Element wird oft „Wurzel“ (engl. „root“), „Anker“ oder „Kopf“ der Liste genannt
- enthält die Informationen
- Länge
- erstes Element
Implementierung
Listenoperationen
Suchen
- Durchlaufen der Liste
- Bis das gewünschte Element gefunden wurde
- Oder das Ende der Liste erreicht ist
- Laufzeit: O(n)
Einfügen
- Elemente werden nur „eingehängt“
- Einfügen „hinter“ bekannter Stelle ist O(1). Position ist durch Pointer bekannt.
- Einfügen an unbekannter Stelle ist O(n).
- Warum? Position muss erst gesucht werden: Kosten O(n)
Entfernen
- Beim Entfernen wird ein Element, dessen Position bekannt ist, aus der Liste entfernt
- Laufzeit Entfernen bei bekannter Position: O(1)
- Laufzeit Entfernen bei unbekannter Position: O(n)
Versetzen eines Elements
- Um bei Arrays die Reihenfolge der Elemente zu ändern, müssen alle Elemente dazwischen verschoben werden.
- Bei verketteten Listen werden Elemente einfach versetzt
- Laufzeit bei bekannten (Pointern an) Positionen: O(1)
- (statt O(k), k Anzahl der Stellen, bei Arrays)
- Es gibt zahlreiche Variationsmöglichkeiten bei der Implementierung.
- “Beste” Variante hängt vom Problem ab.
Struct Definition für Elemente (Namenskonvention _typename):
/* Datentyp für einfach verkettete Liste */
typedef struct _slist {
int value; // Daten
struct _slist *next; // Nachfolger
} slist;
slist meine_liste; // Deklaration
Durchlaufen der linked list:
- Anfang an der Wurzel
- Solange wie ein Nachfolger existiert
- Gib den Wert aus
- Gehe zum Nachfolger
- wenn kein Nachfolger existiert bzw. NULL-Pointer -> fertig
typedef struct _slist {
int value; // Daten
struct _slist *next; // Nachfolger
} slist;
slist *root, *tmp;
tmp = root; // Anfang an der Wurzel
while(tmp != NULL) { // Solange Nachfolger
printf("%d\n", tmp->value); // Wert
tmp = tmp->next; // Nächstes Element
}
Minimale Implementierung:
Datentyp für das erste Element (etwas modifiziert)
typedef struct _list_el {
int value; // Daten
struct _list_el *next; // Nachfolger
} list_el;
head (Kopfzeiger): Zeigt auf das erste Element der Liste.
typedef struct _list {
int count; // Anzahl Listeneinträge
list_el *first; // Erstes Element der Liste
} list;
Methoden / Funktionen:
Initialisieren
list * warenliste = calloc(1, sizeof(list));
void init_list(list *list_pointer){
list_pointer->first = NULL;
list_pointer->count = 0;
}
init_list(warenliste);
Find element
- Durchlaufen
Insert element
- Neuen Knoten anlegen
- Knoten initialisieren
- Knoten einfügen
list * warenliste = calloc(1, sizeof(list));
void list_insert(list *list_pointer, int value){
list_el * new = (list_el *) calloc(1, sizeof(list_el));
new->value = value;
new->next = list_pointer->first;
list_pointer->first = new;
list_pointer->count++; +
}
list_insert(warenliste, 100);
- Delete element // Löschen
Ausgeben
list * warenliste = calloc(1, sizeof(list));
void list_print(list *list_pointer){
list_el *tmp = list_pointer->first;
while(tmp) {
printf(“cur: %d “, tmp->value);
tmp = tmp->next;
} printf(“\n“);
}
list_print(warenliste);
Implementierungsvarianten
- es gibt Zahlreiche Möglichkeiten
- "Beste Variante" hängt von Problem ab
Minimale Implementierung:
- head (Kopfzeiger): Zeigt auf das erste Element der Liste.
- Methoden / Funktionen:
- Find element
- Insert element
- Delete element
Verkette Liste mit extra Wurzel
- Allerdings braucht man häufig weitere Informationen
- Anzahl (
#) Listenelemente - Letztes Element der Liste
- Anders als bei Arrays. Bei Array ist durch initialisierung Länge klar definiert
- Anzahl (
- Lösung:
- Separate Wurzel für Verwaltungsinformation
- funktioniert wie ein Inhaltsverzeichnis
- Separate Wurzel für Verwaltungsinformation
Einfacher Kopfzeiger
- !introprog-v04-listen, p.118
- head zeigt auf das erste Element.
- Das Ende der Folge ist durch einen leeren Zeiger (Wert = NULL) gekennzeichnet.
- Die leere Folge wird dann durch einen leeren Kopfzeiger repräsentiert.
- Nichtleere Folge
- Hinweis zur Implementierung:
- head muss immer auf das erste Element zeigen (Beachte z.B. insert und delete)
zyklische Verkettung
- !introprog-v04-listen, p.120
- Man kann die Zeigerkette schließen
- Das erleichtert das Ablaufen in vielen Fällen.
- letztes Element zeigt auf erstes
- Kopfzeiger mit Nullelement (dummy)
- !introprog-v04-listen, p.128
- Neben dem Kopfzeiger wird ein Nullelement verwendet, jedoch mit zyklischer Verkettung.
- Nicht leere Folge
- Auf diese Weise lassen sich viele Listenoperationen recht kompakt und elegant formulieren.
doppelt verkettete Listen
- Soll eine Folge in beiden Richtungen effizient abgelaufen werden können, so ist eine Doppelverzeigerung erforderlich.
Implementierungsvarianten
- Kopfzeiger ohne Nullelement, ohne Zyklus
!introprog-v04-listen, p.149 - Kopfzeiger auf Nullelement, zyklisch verkettet
!introprog-v04-listen, p.149
Merkmale:
Stack (IntroProg)
- Stack: Datenstruktur, welche effizientes Entfernen in der umgekehrten Einfügereihenfolge ermöglicht.
- Last-In-First-Out (LIFO); First-In-Last-Out (FILO) Datenstruktur
- Methoden:
push/pop - Einsatzbereiche:
- Tellerstapeln
- Browser Historie
- Funktionsaufrufe! U.a. Bei der Rekursion
- Kartenstapel
Implementierung
- Die Implementierung kann als Liste erfolgen:
- push fügt am Kopf ein neues Elemente ein
- pop entnimmt das als Letztes eingefügte Element
- Beide Operationen können in O(1) durchgeführt werden.
- head ist gleichzeitig "top of stack".
Implementierung als Array
!200
- Auch in einem Array können push und pop mit Laufzeit O(1) implementiert werden.
- Nachteil: Max. Stackgröße ist fest, d.h. der Stapel kann "überlaufen" (stack overflow).
- Zugriff auf Element kann jedoch effizienter sein, als mit linked list.
Queue
- Queue: Datenstruktur, welche effizientes Entfernen in der Einfügereihenfolge ermöglicht.
- First-In-First-Out (FIFO) Datenstruktur.
- Zugriff durch Methoden
enqueue/dequeuerealisiert. - Einsatzbereiche:
- Mensa
- Verwaltung
- Druckjobs
- Wursttheke
- Implementierung durch linked list möglich
- !introprog-v04-listen, p.161
- Auch hier gelingt die Implementierung von enqueue und dequeue mit konstanter Laufzeit O(1).
- Array-Implementierung der Warteschlange üblicherweise als Ringpuffer (Ringbuffer) realisiert.
- Es werden zwei Zeiger (Indizes) mitgeführt, die auf den Anfang bzw. das Ende der Warteschlange zeigen.
- Nachteil: Maximale Größe ist fest
- Zugriff auf Elemente kann effizienter sein als mit Linked Lists
!introprog-v04-listen, p.163
Dynamische Datenstrukturen
- Beispiele für dynamische Datenstrukturen:
- Liste
- Baum
- Graph
- …
- Eigenschaften
- Erweiterbar
- Schnelles Einfügen
- Löschen möglich
dynamic Array
Erweiterung des klassischen Arrays für effizientes Löschen / Einfügen am Ende.
- Unterscheidung zwischen capacity und legth
- capacity: Größe im Speicher
- length: Anzahl der tatsächlich verwendeten Elemente
- Einfügen und Löschen am Ende sind ≈ O(1).
- ABER: Einfügen und Löschen an einer beliebigen Stelle immer noch teuer.
Records
- Zusammenfassung von zusammengehörigen Daten in eigenen Datentyp durch struct
- Beispiel Produkte mit Namen und Preis:
struct produkt { // Definition
char name[255];
float preis;
};
struct produkt beispiel; // Deklaration
- Zugriff durch Selektor
.(Punkt)
beispiel.preis = 0.79;
strncpy(beispiel.name, "Apfel", 255);
printf("Ware %s mit Preis %f\n",
beispiel.name, beispiel.preis);
- Beispiel Produkte mit Namen und Preis mit Pointer
struct produkt {
char name[255];
float preis;
};
struct produkt beispiel;
struct produkt warenkorb[100];
struct produkt *ware = warenkorb;
- Zugriff bei Pointern durch slektor
->("Pfeil")
printf("Produkt %s mit Preis %f\n",
ware->name, ware->preis);
```
- Typdefinition
- oft sinnvoll, eigene Typen zu definiere mittels `typedef`
- Beispiel
```c
typedef struct produkt {
char name[255];
float preis;
} produkt_t;
// Variablendeklaration
produkt_t produkt1, produkt2;
```
- Warum? Bessere Lesbarkeit, bessere Dokumentation
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/tree/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Bäume
>[!info] Definition
>Ein **Baum** ist eine hierarchische Datenstruktur, die aus Knoten besteht. Es gibt einen einzigen **Wurzelknoten**, von dem aus jeder andere Knoten über genau einen Pfad erreichbar ist. Jeder Knoten kann mehrere Kindknoten haben, wobei die Anzahl der Kindknoten je nach Baumtyp variieren kann:
>- **Binärer Baum:** Jeder Knoten hat höchstens zwei Kindknoten (linkes und rechtes Kind).
>- **Allgemeiner Baum:** Jeder Knoten kann eine beliebige Anzahl von Kindknoten haben.
>[!info] Definition
>Ein **t-ärer Baum** ist entweder die leere Menge oder ein Knoten (ein Objekt), welcher ein Datum und t Kindbäume enthält, welche t-äre Baume sind.
>[!info] Definition
>Ein **Binär-Baum** ist formal auch ein 2-ärer Baum.
- **Knotenorientierte** Bäume: Daten liegen in den Knoten.
- z.B. Speicherung von unterschiedlich großer Werte
- **Blattorientierte** Bäume: Daten liegen nur in den Blättern. − Innere Knoten enthalten nur Zugriffsinformation
- **Kantenorientierte** Bäume: Daten in den Kanten
- z.B. sind auf einer Karte die Kanten Entfernungen
## Warum gibt es trees?
- grundlegendes Problem der Programmierung:
- Speicherung von Datensätzen
- Listen oft nicht ausreichend, da O(n) zu langsam ist (suchen, einfügen, löschen, etc.).
- Beispiele
- Stammbaum
- Dateisysteme
- Entscheidungsbäume
- Suchbäume, z.B. für Lexikon, Daten
- Rekursionsbäume
- Anforderungen an Datenstruktur
- Schneller Zugriff, d.h. schneller als O(n)
- Schnelles Einfügen neuer Datensätze
- Schnelles Löschen bestehender Datensätze
## Binärbaum
- !introprog-v05-baeume, p.9
>[!example] Definition
>- Ein Binärbaum T ist eine Struktur, die auf einer endlichen Menge definiert ist. Diese Menge nennt man auch die Knotenmenge des Binärbaums.
>- Die leere Menge ist ein Binärbaum. Dieser wird auch als leerer Baum bezeichnet.
>- Ein Binärbaum ist ein Tripel $(v,T_{1}, T_{2})$, wobei $T_{1}$ und $T_{2}$ Binärbäume mit disjunkten Knotenmengen $V_{1}$ und $V_{2}$ sind, d.h. Und $V_{1} ∩ V_{2} = ∅$, und $v ∉ V_{1} ∪ V_{2}$ Wurzelknoten heißt. Die Knotenmenge des Baums ist dann $\{v\} ∪ V_{1} ∪ V_{2}$ . $T_{1}$ heißt linker Unterbaum von $v$ und $T_{2}$ heißt rechter Unterbaum von $v$.
- häufig lässt man die leeren Bäume in der Darstellung eines Binärbaums weg
### Liste der Begriffe
| Begriff | Erläuterung | Beispiel |
| ---------------------------- | ------------------------------ | ----------------------------------- |
| Vorgänger (predecessor) | - | A ist Vorgänger von B |
| Nachfolger (successor) | - | B ist Nachfolger von A |
| Wurzel (root) | kein Vorgänger | A |
| Blatt (leaf) | kein Nachfolger | D, H, I, J, K |
| interner Knoten (inner node) | alle Nachfolger besetzt | A, B, C, G |
| Randknoten (boundary node) | nicht alle Nachfolger besetzt | D, E, F, H, I, J, K |
| Pfad (path) | Knotenfolge von einem Anfangs- | Pfad von der Wurzel nach F: A, C, F |
| | bis zum Endknoten | |
| Pfadlänge (path length) | Anzahl der Kanten des Pfads | Pfadlänge von A nach F: 2 |
| Tiefe eines Knotens (depth) | Pfadlänge zur Wurzel | Tiefe von F: 2 |
| Höhe eines Baumes (height) | Größte Tiefe | 3 |
| Höhe eines Knotens v | Höhe des Teilbaums von v | Höhe von F: 1 |
### Darstellung im Rechner
- Schlüssel *key* und ggf. weitere Daten
- Zeiger *lc(v)* bzw. *rc(v)* auf linkes bzw. rechtes Kind von *v*
- Elterzeiger *p(v)* auf Vater/Mutter von *v* (blau) −
- Wurzelzeiger *root(T)*
- !introprog-v05-baeume, p.13
### Binäre Suchbäume
- Verwende Binärbäume
- Speichere Schlüssel "geordnet"
- Binäre Suchbaumeigenschaft
- Sei x ein Knoten im binären Baum
- Ist y ein Knoten im linken Unterbaum von x, dann gilt key(y) ≤ key(x)
- Ist y ein Knoten im rechten Unterbaum von x, dann gilt key(y) > key(x)
- unterschiedliche Suchbäume
- !introprog-v05-baeume, p.15
- Schlüsselmenge: 3,4,6,7,7,9
- Wirerlauben mehrfache Vorkommen desselben Schlüssels
### Operationen
#### Durchlaufen
- Gegeben binärer Suchbaum
- Wie kann man alle Schlüssel aufsteigend sortiert in O(n) Zeit ausgeben
Inorder-Tree-Walk(x) //Aufruf über Inorder-Tree-Walk(root(T))
- if x ≠ nil then
- Inorder- Tree-Walk(lc(x))
- Ausgabe key(x)
- Inorder-Tree-Walk(rc(x))
- Laufzeit
- Ausgeben aller Schlüssel
- Gegeben binärer Suchbaum
- Wie kann man alle Schlüssel aufsteigend Sortiert in O(n) Zeit ausgeben?
- !introprog-v05-baeume, p.56
- Der Algorithmus ist optimal. Schneller gehts nicht
#### Suchen – Rekursiv
- if x =nil or k=key(x) then return x
- if k<key(x) then return Baumsuche(lc(x),k) // Entweder links
- else return Baumsuche(rc(x),k) // oder rechts
- funktioniert nur, wenn sortiert
- Laufzeit
- wenn Suchbaum balanciert ist O(h)
- Höhe *h* von Baum ist Zweierpotenz aber umgekehrt, also log* (Anzahl Knoten)
- Laufzeit ist durch Höhe beschränkt
#### Suchen – Iterativ
IterativeBaumsuche(x,k)
- while x ≠ nil and k ≠ key(x) do
- if k < key(x) then x ← lc(x)
- else x ← rc(x)
- return x
#### MIN/MAX Suche
MinimumSuche(x)
- ehile lc(x) ≠ nil do x ← lc(x)
- return x
MaximumSuche(x)
- while rc(x) ≠ nil do x ← rc(x)
- return x
#### Nachfolgersuche
- Nachfolger bzgl. Inorder-Tree-Walk
- Wenn alle Schlüssel unterschiedlich, dann ist das der nächstgrößere Schlüssel (nicht notwendigerweise das direkte nächste Kind!)
- Fall 1 (rechter Unterbaum von x nicht leer): Dann ist der linkeste Knoten im rechten Unterbaum der Nachfolger von x
- Fall 2 (rechter Unterbaum von x leer und x hat Nachfolger y): Dann ist y der erste Knoten auf dem Pfad zur Wurzel, der größer als x ist
Nachfolgersuche(x)
- if rc(x) ≠ nil then return Minimumsuche(rc(x))
- y ← p(x)
- while y ≠ nil and x=rc(y) do
- x ← y
- y ← p(y)
- return y
#### Vorgängersuche
- Analog zur Nachfolgersuche
- Daher ebenfalls O(h) Laufzeit
- Einfügen
- Ähnlich wie Baumsuche: Finde Blatt, an das neuer Knoten angehängt wird
- Danach wird **nil**-Zeiger durch neues Element ersetzt
```
Einfügen(T,z)
1. y ← nil; x ← root(T)
2. while x ≠ nil do
3. y ← x
4. if key(z) <= key(x) then x ← lc(x)
5. else x ← rc(x)
6. p(z) ← y
7. if y=nil then root(T) ← z
8. else
9. if key(z)<= key(y) then lc(y) ← z
10. else rc(y) ← z
```
#### Löschen
- gegeben: binärer Suchbaum und zu löschendes Element z
- 3 unterschiedliche Fälle
1. Zu löschendes Element z hat keine Kinder
!250
- entferne Element z
1. Zu löschendes Element z hat ein Kind
!250
- ersetze Element z durch das Kind
3. Zu löschendes Element z hat zwei Kinder
!250
1. Bestimme Nachfolger von z
2. Entferne Nachfolger von z
3. Ersetze z durch Nachfolger
- Pseudocode
```
Löschen(T, z)
1. if lc(z) = nil or rc(z) = nil then y ← z
2. else y ← NachfolgerSuche(z)
3. if lc(y) ≠ nil then x ← lc(y)
4. else x ← rc(y)
5. if x ≠ nil then p(x) ← p(y)
6. if p(y) = nil then root(T) ← x
7. else if y = lc(p(y)) then lc(p(y)) ← x
8. else rc(p(y)) ← x
9. key(z) ← key(y)
```
### Höhe eines Binärbaumes
>[!example] Definition
>Die **Höhe eines Binärbaumes** mit Wurzel v ist die Länge (Anzahl der Kanten) des längsten einfachen Weges (keine mehrfach vorkommenden Knoten) von der Wurzel zu einem Blatt #Definition
- Beispiel
- Ein Baum hat die Höhe 0
- Damit gilt: !100
- Höhe eines Baumes mit Wurzel v und Teilbäumen A und B ist 1 + max(Höhe(A), Höhe(B))
- Baum der Höhe 3: !100
## Dynamische Bäume
- Ein Grundlegendes Datenbank-Problem
- Speicherung von Datensätzen
- Beispiel
- Kundendaten (Name, Adredse, Wohnort, Kundennummer, offene Rechnungen, offene Bestellungen,…)
- Anforderungen
- Schneller Zugriff
- Schnelles Einfügen neuer Datensätze
- Schnelles Löschen bestehender Datensätze
### Dynamische Baumoperationen
- Binäre Suchbäume
- Aufzählen der Elemente mit Inorder-Tree-Walk in O(n) Zeit
- Suche in O(h) Zeit
- Minimum/Maximum in O(h) Zeit
- Vorgänger/Nachfolger in O(h) Zeit
- Dynamische Operationen?
- Einfügen und Löschen
- Müssen Suchbaumeigenschaft aufrecht erhalten
- Auswirkung auf Höhe des Baums?
## Traversierung von Bäumen
>[!info] Definition
> Die Traversierung eines Baum beschreibt die Reihenfolge in der alle Knoten eines Baumes besucht werden
- Pre-order: Knoten -> Links -> Rechts
- Post-order: Links -> Rechts -> Knoten
- In-order: Links -> Knoten -> Rechts
- Level-order: Schicht nach Schicht von der Wurzel aus
## Tiefen- und Breitensuche in Bäumen
!AlgoDat-LectureNotes, p.62
### Kernkonzept
>[!info] Tiefensuche in Bäumen
>Bei der Tiefensuche (*depth-first search*) geht die Suche zunächst in die Tiefe und erst mit niedrigerer Präferenz in die Breite.
>Man geht von einem Knoten zu dem Nachfolger, von dort wieder zu dessen Nachfolger usw. bis man an ein Blatt stößt. Dann geht man einen Schritt zurück und besucht den nächsten Nachfolger.
>!AlgoDat-LectureNotes, p.58
>[!info] Breitensuche in Bäumen
>Bei der Breitensuche (*breadth-first search*) geht die SUche zunächst in die Breite und erst mit niedrigere Präferenz in die Tiefe.
>Man geht von einem Knoten der Reihe nach zu allen direkten Nachfolgern und erst dann zu deren Nachfolgern.
>!AlgoDat-LectureNotes, p.58
### Pseudocode
**Tiefensuche:**
1 // Tiefensuche
2 D : ein Stapel (Stack)
3 D ← {Wurzel}
4 while D̸ = ∅
5 v ← D.get () // pop()
6 besuche Knoten v
7 for all w Nachfolger von v
8 D.put(w) // push()
9 end
10 end
**Rekursive Tiefensuche:**
1 procedure DFS(v)
2 besuche Knoten v
3 for all w Nachfolger von v
4 DFS(w)
5 end
6 end
7
8 Aufruf durch: DFS( Wurzel )
**Breitensuche:**
1 // Breitensuche
2 D : eine Warteschlange (Queue)
3 D ← {Wurzel}
4 while D̸ = ∅
5 v ← D.get () // dequeue()
6 besuche Knoten v
7 for all w Nachfolger von v
8 D.put(w) // enqueue()
9 end
10 end
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/c-streams/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# C-Streams
- jedes laufende C-Programm (= Prozess) hat voreingestellt drei Kanäle für Ein-/Ausgabe:
- `stdi` Standardeingabe
- meist Tastatur
- `stdout` Standardausgabe
- meist Bildschirm
- `stderr` Standardfehlerausgabe
- meist Bildschirm
- separat umleitbar im Gegensatz zu `stdout`
- !introprog-v06-c-dateien, p.25
- Die Standardkanäle sind umlenkbar:
```shell
$ ./meinprog < InFile
$ ./meinprog > OutFile
$ ./meinprog 2> OutFile
// bash Umleiten von stderr
$ ./meinprog &> OutFile
// bash Umleiten von stderr und stdout
($ ./meinprog >& OutFile
// tcsh Umleiten von stderr und stdout)
```
- Die Standardkanäle sind kombinierbar: `$ ./meinprog < InFile > OutFile`
- Unix Tools: `cat, sort, more, less, grep, wc, tail, cut, sed, split, uniq
- Ausgabe von ./meinprog1 als Eingabe für sort verwenden: `$ ./meinprog1 | sort > OutFile`
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/unix-befehle/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# wichtige Unix Befehle
- **ls**: List - Listet den Inhalt eines Verzeichnisses auf.
- Beispiel: ls (zeigt den Inhalt des aktuellen Verzeichnisses).
- Zusätzliche Optionen:
- ls -l: Zeigt detaillierte Informationen wie Berechtigungen, Besitzer, Größe und Änderungsdatum.
- ls -a: Zeigt auch versteckte Dateien (die mit . beginnen).
- ls -lh: Zeigt Dateigrößen in einem menschenlesbaren Format (z. B. KB, MB, GB).
- Beispiel: ls -lah (kombiniert alle obigen Optionen).
- **mv**: Move - Verschiebt Dateien oder Verzeichnisse oder benennt sie um.
- Beispiel: mv datei.txt neuer_ort/ (verschiebt die Datei datei.txt in den Ordner neuer_ort).
- **cp**: Copy - Kopiert Dateien oder Verzeichnisse.
- Beispiel: cp quelle.txt ziel.txt (kopiert quelle.txt nach ziel.txt).
- **mkdir**: Make Directory - Erstellt ein neues Verzeichnis.
- Beispiel: mkdir neuer_ordner (erstellt ein Verzeichnis namens neuer_ordner).
- **rm**: Remove - Löscht Dateien oder Verzeichnisse.
- Beispiel: rm datei.txt (löscht die Datei datei.txt).
- **rmdir**: Remove Directory - Löscht leere Verzeichnisse.
- Beispiel: rmdir leerer_ordner (löscht den Ordner leerer_ordner, wenn er leer ist).
- **find**: Suchen - Sucht Dateien oder Verzeichnisse basierend auf verschiedenen Kriterien.
- Beispiel: find /pfad/zum/suchen -name "datei.txt" (sucht nach einer Datei mit dem Namen datei.txt im Verzeichnis /pfad/zum/suchen).
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/sortieralgorithmen/merge-sort/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# MergeSort
>[!example] Kernkonzept
`MergeSort()`Mergesort teilt das zu sortierende Array rekursiv in Hälften, bis nur noch einzelne Elemente übrig sind. Diese sind als kleinstmögliche, bereits sortierte Einheiten anzusehen. Ähnlich wie ein binary tree. Anschließend beginnt der Zusammenführungsprozess (Mergen): Jeweils zwei sortierte Teilarrays werden dabei elementweise verglichen und zu einem größeren, sortierten Array verschmolzen. Dieser Vorgang wiederholt sich so lange, bis schließlich ein einzelnes, vollständig sortiertes Array entsteht. Dadurch erhält man eine stabile Sortierung mit einer Laufzeit von O(n log n).
- stabiler Sortieralgorithmus
-
## Rekursiv
$$
\begin{array}{ll}
\textbf{MergeSort}(A, p, r) & \quad \triangleright \text{Sortiere } A[p, \ldots, r] \\
1. \quad \textbf{if } p \geq r \textbf{ then} & \quad \triangleright \text{p} \geq \text{r, dann nichts zu tun} \\
2. \quad q \gets \lfloor (p + r) / 2 \rfloor & \quad \triangleright \text{Berechne Mitte} \\
3. \quad \textbf{MergeSort}(A, p, q) & \quad \triangleright \text{Sortiere linke Hälfte} \\
4. \quad \textbf{MergeSort}(A, q + 1, r) & \quad \triangleright \text{Sortiere rechte Hälfte} \\
5. \quad \textbf{Merge}(A, p, q, r) & \quad \triangleright \text{Zusammenfügen} \\
\end{array}
$$
$$
\begin{array}{ll}
\textbf{Merge}(A, p, q, r) & \quad \triangleright \text{Zusammenfügen von } A[p, \ldots, q], A[q+1, \ldots, r] \\
1. \quad \text{Array } B & \quad \triangleright \text{Hilfsarray zum Mergen Länge } r-p+1 \\
2. \quad i \gets p, j \gets q+1 & \quad \triangleright \text{Hilfsvariablen für linke/rechte Hälfte von A} \\
3. \quad b \gets 1 & \quad \triangleright \text{Hilfsvariable für Array B} \\
4. \quad \textbf{while } i \leq q \textbf{ and } j \leq r \textbf{ do} & \quad \triangleright \text{Solange Einträge auf beiden Seiten} \\
5. \quad \quad \textbf{if } A[i] \leq A[j] \textbf{ then} & \quad \triangleright \text{links kleiner} \\
6. \quad \quad \quad B[b++] \gets A[i++] & \quad \triangleright \text{Zuweisung nach B} \\
7. \quad \quad \textbf{else} & \quad \triangleright \text{rechts kleiner} \\
8. \quad \quad \quad B[b++] \gets A[j++] & \quad \triangleright \text{Zuweisung nach B} \\
9. \quad \textbf{while } i \leq q \textbf{ do} & \quad \triangleright \text{Noch Einträge auf der linken Seite} \\
10. \quad \quad B[b++] \gets A[i++] & \quad \triangleright \text{Zuweisung nach B} \\
11. \quad \textbf{while } j \leq r \textbf{ do} & \quad \triangleright \text{Noch Einträge auf der rechten Seite} \\
12. \quad \quad B[b++] \gets A[j++] & \quad \triangleright \text{Zuweisung nach B} \\
13. \quad A[p, \ldots, r] \gets B & \quad \triangleright \text{Kopiere Hilfsarray B nach A} \\
\end{array}
$$
## Iterativ
$$
\begin{array}{ll}
\textbf{IterativMergeSort}(A) & \quad \triangleright \text{Sortiere } A[1, \ldots, n] \\
1. \quad \text{step} \gets 1 & \quad \triangleright \text{Hilfsvariablen für Schrittweite} \\
2. \quad \textbf{while } \text{step} < n \textbf{ do} & \quad \triangleright \text{Solange noch nicht das ganze Array sortiert ist} \\
3. \quad \quad \text{left} \gets 1 & \quad \triangleright \text{Initialisierung der linken Grenze} \\
4. \quad \quad \textbf{while } \text{left} \leq n - \text{step} \textbf{ do} & \quad \triangleright \text{Schleife zum Sortieren von Teilarrays der Länge step von left an} \\
5. \quad \quad \quad \text{middle} \gets \text{left} + \text{step} - 1 & \quad \triangleright \text{Hilfsvariable für Mitte} \\
6. \quad \quad \quad \text{middle} \gets \min(\text{middle}, n) & \quad \triangleright \text{Arraygrenzen nicht überschreiten} \\
7. \quad \quad \quad \text{right} \gets \text{left} + 2 \cdot \text{step} - 1 & \quad \triangleright \text{Hilfsvariable für rechte Grenze} \\
8. \quad \quad \quad \text{right} \gets \min(\text{right}, n) & \quad \triangleright \text{Arraygrenzen nicht überschreiten} \\
9. \quad \quad \quad \text{merge}(A, \text{left}, \text{middle}, \text{right}) & \quad \triangleright \text{Merge} \\
10. \quad \quad \quad \text{left} \gets \text{left} + 2 \cdot \text{step} & \quad \triangleright \text{Verschieben der linken Grenze} \\
11. \quad \text{step} \gets \text{step} \cdot 2 & \quad \triangleright \text{Schrittweite erhöhen} \\
\end{array}
$$
## Laufzeit
>[!abstract]
>Algorithmus MergeSort hat eine Laufzeit von O(n log n).
- Man kann ein Array so oft teilen wie $\log_{2}(\text{Länge Array})$ -> Logarithmus dualis
- `MergeSort(A,1,n)` für Feld `A[1...n] `
- `T(m) = maximale Laufzeit bei Eingabe A, p, r mit r-p+1=m`
$$
\begin{array}{ll}
\textbf{MergeSort}(A, p, r) & \quad \textbf{Laufzeit:} \\
1. \quad \textbf{if } p < r \textbf{ then} & \quad 1 \\
2. \quad \quad q \gets \lfloor (p + r) / 2 \rfloor & \quad 1 \\
3. \quad \quad \textbf{MergeSort}(A, p, q) & \quad 1 + T(n/2) \\
4. \quad \quad \textbf{MergeSort}(A, q + 1, r) & \quad 1 + T(n/2) \\
5. \quad \quad \textbf{Merge}(A, p, q, r) & \quad \leq c \cdot n \\[10pt]
& \quad \leq 2T(n/2) + c \cdot n \\
\end{array}
$$
### Beweis für Laufzeit O(n log n)
- Die Laufzeit für T(1) und T(2) ist konstant.
- Sei also T(2) ≤ C‘ und C* ≥ max{c,C‘}. Wir zeigen per Induktion,
- T(n) ≤ C*n log n für alle n≥2
- (I.A.) für n=2 gilt T(2) ≤ C‘ ≤ C* 2 log 2.
- (I.V.) Für Eingabelänge m<n ist die Laufzeit T(m) ≤ C* m log m.
- (I.S.) Es gilt T(n) ≤ 2 T(n/2) + cn. Nach (I.V.) gilt
- T(n) ≤ 2 C* n/2 log(n/2) + cn
- ≤ C* n (log(n)-1) + cn
- ≤ C* n (log(n)-1) + C*n = C* n log(n)
- Also gilt T(n) = O(n log n), `[da für n≥n =2, T(n) ≤ C*n log n ist ]`
## Iterativ vs. Rekursiv
- Laufzeiten (gemessen)
| Anzahl | Sortierzeiten [msec] Rekursiv | Sortierzeiten [msec] Iterativ |
|--------|-------------------------------|-------------------------------|
| 100 | 4.50 | 3.72 |
| 200 | 9.98 | 8.36 |
| 400 | 21.88 | 18.68 |
| 800 | 47.92 | 41.24 |
| 1600 | 103.83 | 91.16 |
| 3200 | 224.86 | 199.01 |
- Die Laufzeit unterscheidet sich nur unswesentlich
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/logarithmus-dualis/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Logarithmus dualis
**Der logarithmus dualis** (logarithmus zur Basis 2) misst, wie oft man eine Größe halbieren muss, um auf 1 zu kommen. Wenn du zum Beispiel 32 hast, dann ist der log₂(32) = 5, weil du fünfmal halbst: 32 → 16 → 8 → 4 → 2 → 1. Er taucht in der Informatik häufig auf, weil viele Algorithmen auf Teilungen in Hälften beruhen, wodurch die Laufzeit in etwa mit log₂(n) skaliert.
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/wie-beweist-man-die-korrektheit-eines-algorithmus/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Wie beweist man die Korrektheit eines Algorithmus?
- es ist **nicht** möglich einen allgemeinen Algorithmus zu erschaffen, der die Korrektheit eines Algorithmus beweist
- mathematischer Beweis
- Definition: Ein Beweis ist eine Herleitung einer Aussage aus bereits bewiesenen Aussagen und/oder Grundannahmen (Axiomen).
- Man versucht zu beweisenden Sachverhalt auf etwas zurückzuführen, dass bereits bewiesen ist -> Vollständige Induktion
- mit Korrektheitsbeweisen
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/korrektheitsbeweis/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Korrektheitsbeweis
## 1. Was bedeutet Korrektheit?
- Ein Algorithmus heißt **korrekt**, wenn er **für jede zulässige Eingabe** in **endlicher Zeit** (Halteproblem) **das gewünschte Ergebnis** liefert (partielle bzw. totale Korrektheit).
- Es gibt somit zwei Teilaspekte der Korrektheit:
1. **Terminierung**: Der Algorithmus muss für alle Eingaben enden (das Halteproblem).
2. **Partielle Korrektheit**: Das ausgegebene Ergebnis muss bei Beendigung korrekt sein.
- WICHTIG: **Problembeschreibung muss exakt definiert sein**
### **Unterschied zwischen partielle und totale Korrektheit**
- **Partielle Korrektheit** garantiert, dass das Ergebnis korrekt ist, **falls** der Algorithmus anhält.
- **Totale Korrektheit** setzt die partielle Korrektheit voraus, zeigt aber zusätzlich, dass der Algorithmus immer anhält.
---
## 2. Das Halteproblem (Terminierung)
- Ein Algorithmus, der nie anhält (z. B. in einer Endlosschleife), kann kein Ergebnis liefern und ist daher nicht korrekt.
- **Beispiel**: *Collatz-Algorithmus* – seine Terminierung ist bis heute nicht bewiesen.
- **Gegenbeispiel**: *Algorithmus der ägyptischen Multiplikation* hält für alle natürlichen Eingaben `n` und `m`, da die Schleifenvariable in jedem Durchlauf strikt sinkt und schließlich die Schleifenbedingung verletzt wird.
>[!abstract] **Wichtige Schritte bei Terminierungsbeweisen**
>- **Schleifenvariable** identifizieren und zeigen, dass sie sich bei jedem Durchlauf in Richtung der Abbruchbedingung bewegt.
>- **Abbruchbedingung** formulieren und beweisen, dass sie erreicht wird.
### Terminierungsbeweis beim Beispiel (ägyptische Multiplikation)
1. **Schleifenvariable**: `x` (entspricht `n` im Input).
2. **Eingangsbelegung**: `x0 = n`.
3. **Abbruchbedingung**: `while (x >= 1)`.
4. **Beobachtung**:
- `x` bleibt eine ganze Zahl.
- Pro Durchlauf wird `x` entweder halbiert (wenn gerade) oder `(x - 1)` halbiert (wenn ungerade). In beiden Fällen verringert sich der Wert garantiert.
- Nach maximal `n` Schritten (bzw. einer Funktion, die von `n` abhängt) wird `x` so klein, dass die Schleife endet.
5. **Ergebnis**: Der Algorithmus terminiert bei jeder natürlichen Zahl `n`.
---
## 3. Partielle Korrektheit
Damit der Algorithmus nicht nur anhält, sondern auch das **richtige Ergebnis** berechnet, muss man zeigen, dass die ausgegebene Variable tatsächlich dem gewünschten Wert entspricht. Beim Beispiel der ägyptischen Multiplikation soll das Produkt `n * m` berechnet werden.
---
## 4. Schleifeninvariante
### Definition
- Eine **Schleifeninvariante** ist eine Eigenschaft (oder ein Wert), die/der **vor** und **nach** jedem Schleifendurchlauf gilt.
- Formell heißt das:
1. Zu Beginn der Schleife (Initialisierung) ist die Invariante erfüllt.
2. Falls die Invariante **vor** einem Durchlauf gilt, dann gilt sie auch **nach** diesem Durchlauf.
3. Gilt die Invariante noch, wenn die Schleife abbricht, so liefert sie Informationen über den Endzustand.
### Beispiel-Invariante bei der ägyptischen Multiplikation
- Man wählt als Schleifeninvariante den Ausdruck
$$x \cdot y + p.$$
Hier sind `x`, `y` und `p` Variablen, die im Algorithmus in jedem Schleifendurchlauf geändert werden.
- **Idee**:
- Durch Halbieren von `x` und Verdoppeln von `y` bleibt das Produkt `x * y` konstant.
- Falls `x` ungerade ist, wird ein passender Anteil (`y`) zu `p` addiert und gleichzeitig `x` durch `(x - 1)` halbiert.
Dadurch gleicht sich das Produkt wieder aus.
- Insgesamt bleibt `x * y + p` vor und nach jedem Schleifendurchlauf gleich.
### Beispiel-Invariante bei der Maximumsuche
$$
\begin{array}{l l}
& \textbf{Algorithmus Max-Search}(A) \\
1. & \text{max} \leftarrow 1 \\
2. & \textbf{for } j \leftarrow 2 \textbf{ to } \text{length}(A) \textbf{ do} \\
3. & \quad \textbf{if } A[j] > A[\text{max}] \textbf{ then } \text{max} \leftarrow j \\
4. & \textbf{return } \text{max} \quad \text{// max ist der Index eines maximalen Elements} \\
\end{array}
$$
- **Schleifeninvariante**
- **Definition**: `A[max]` ist ein größtes Element aus `A[1..j-1]`.
- **Abkürzung**: `A[1..j-1]` bezeichnet das Teilarray von `A[1]` bis `A[j-1]`.
- **Beweis der Schleifeninvariante**
1. **Initialisierung (vor der Schleife)**:
- Zu Beginn ist `j = 2`.
- Das Teilarray `A[1..1]` enthält nur das erste Element (A[1]).
- Es gilt: `max = 1`, also ist `A[max] = A[1]`.
- Die Invariante gilt, da `A[max]` das größte Element aus `A[1..1]` ist.
2. **Erhaltung (während der Schleife)**:
- Angenommen, die Invariante gilt zu Beginn eines Schleifendurchlaufs für ein aktuelles j.
- Es gibt zwei Fälle:
1. **Fall 1**: `A[j] ≤ A[max]`
- Die Bedingung if `A[j] > A[max]` wird nicht erfüllt, und max bleibt unverändert.
- Somit bleibt `A[max]` das größte Element aus `A[1..j]`.
2. **Fall 2**: `A[j] > A[max]`
- Die Bedingung wird erfüllt, und max wird auf `j` gesetzt.
- Nun ist `A[max] = A[j]`, das größte Element aus `A[1..j]`.
- In beiden Fällen bleibt die Schleifeninvariante erhalten.
3. **Abbruch (nach der Schleife)**:
- Am Ende der Schleife gilt `j = length(A) + 1`.
- Die Schleifeninvariante garantiert, dass `A[max]` das größte Element aus `A[1..length(A)]` ist.
- Da max der Index des größten Elements ist, liefert der Algorithmus korrekt max.
---
## 5. Induktionsbeweis (Vollständige Induktion)
Um zu zeigen, dass die Schleifeninvariante tatsächlich zu einem korrekten Ergebnis führt, nutzt man meist einen **Induktionsbeweis**:
1. **Induktionsbasis**:
- Man zeigt, dass die Invariante vor dem ersten Schleifendurchlauf gilt (z. B. `x0 = n`, `y0 = m`, `p0 = 0`, sodass `x0 * y0 + p0 = n * m + 0`).
2. **Induktionsschritt**:
- Angenommen, die Invariante hält nach dem *i*-ten Durchlauf.
- Dann zeigt man, dass sie auch nach dem *(i+1)*-ten Durchlauf gilt.
- Man rechnet also die Änderungen von `x`, `y` und `p` in den zwei Fällen (gerade/ungerade) durch und stellt sicher, dass `x * y + p` sich nicht ändert.
3. **Ergebnis nach Abbruch**:
- Wenn die Schleife beendet ist, gilt `x = 0` (bzw. < 1).
- Die Invariante besagt:
$$
0 \cdot y + p = p.
$$
- Also muss `p = n * m` sein (da die Invariante mit dem Anfangswert `n*m` übereinstimmt).
---
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/heap-intro-prog/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Heap (IntroProg)
>[!abstract] in einer Nussschale
>- Abstrakte Datenstruktur
>- Basiert meist auf einem Baum
>- Jedes Element hat einen Schlüssel (häufig die Elemente selbst), das die Priorität des Elements festlegt
>- Partiell geordneter Baum
>[!example] Definition
>Ein Heap stellt einen Binärbaum in einem Array dar
## Aufbau eines Heaps
!introprog-v09-heapsort, p.8
- **Index 1:** Enthält das erste Element, welches der Wurzel des Baumes entspricht.
- **Index 2:** Zeigt auf das zweite Element, das als linkes Kind der Wurzel angesehen wird.
- **Index 3:** Enthält das dritte Element, welches als rechtes Kind der Wurzel gilt.
- **Weitere Indizes:** Die anschließenden Elemente werden fortlaufend in der Reihenfolge ihrer Aufzählung (von oben nach unten und von links nach rechts) nummeriert.
- daraus resultieren Regeln um im Baum zu navigieren
## Navigation
| Ziel | Berechnung |
| --------- | ----------------------------- |
| Wurzel | $1$ |
| Parent(i) | $\lfloor \frac{i}{2} \rfloor$ |
| Left(i) | $2i$ |
| Right(i) | $2i+1$ |
## Anwendungen
- Sortieren (HeapSort) HeapSort
- Zugriff auf Min/Max in O(1)
- Scheduling
- Etc.
## Max-Heap-Bedingung:
- Die Schlüssel der Kinder eines Knotens sind stets kleiner als die ihres Parent ⇒ an der Wurzel des Baumes ist immer ein Element mit maximalem Schlüssel
!200
- Min-Heap-Bedingung entsprechend
- Serialisieren -> zweidiemnsionale Datenstruktur muss eindimensional gemacht werden. Weil das netzwerkkabel eindimensional ist
## Binäre Halden: Bäume als Arrays
- `Array A[1,…,length(A)]`
- Man kann ein Array als vollständigen Binärbaum interpretieren
- D.h., alle Ebenen des Baums sind voll bis auf die letzte (linksvoll)
- Zwei Attribute: length(A) und heap-size(A), heap-size(A) ≤ length(A)
>[!example] max Heap property
>Für jeden Knoten i außer der Wurzel gilt:
>`A[Parent(i)] ≥ A[i]`
>[!example] min Heap property
>Für jeden Knoten i außer der Wurzel gilt:
>`A[Parent(i)] ≤ A[i]`
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/sortieralgorithmen/heap-sort/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# HeapSort
## Heapify
### Vorraussetzungen
- Die Teilarrays mit Wurzel Left(i) und Right(i) sind Heaps
- `A[i]` ist aber evtl. kleiner als seine Kinder
- `Heapify(A,i)` lässt i „absinken“, so dass die Heap Eigenschaft erfüllt wird
$$
\begin{array}{rl}
& \text{\textbf{Heapify(A,i)}}\\
1. & l \gets \text{left}(i) \\
2. & r \gets \text{right}(i) \\
3. & \text{if } l \leq \text{heap-size}(A) \text{ and } A[l] > A[i] \text{ then} \\
& \quad \text{largest} \gets l \\
4. & \text{else } \text{largest} \gets i \\
5. & \text{if } r \leq \text{heap-size}(A) \text{ and } A[r] > A[\text{largest}] \text{ then} \\
& \quad \text{largest} \gets r \\
6. & \text{if } \text{largest} \neq i \text{ then} \\
7. & \quad \text{swap } A[i] \leftrightarrow A[\text{largest}] \\
8. & \quad \text{Heapify}(A, \text{largest}) \\
\end{array}
$$
### Laufzeit
>[!question] Satz:
>Die Laufzeit von Heapify(A,i) ist O(h), wobei h die Höhe des zu i zugehörigen Knotens in der Baumdarstellung des Heaps ist.
>[!info] **Beweis:** Zeige per Induktion über h, dass die Laufzeit ≤ c∙h ist
>- (I.A.) h=0:
> - Z. 4: largest wird auf i gesetzt
> - Z. 5: Keine Änderung.
> - Z. 6/7: Kein rekursiver Aufruf
> ⇒ Laufzeit ist c.
>- (I.V.) Für Knoten der Höhe h ist die Laufzeit ch.
>- (I.S.) Betrachte Knoten der Höhe h+1.
> - Z. 3-5: largest wird auf i oder auf eines der Kinder von i gesetzt.
> - Z. 6/7: Wenn rekursiver Aufruf durchgeführt, dann mit Kind von i
> - Kind von i hat Höhe h; nach (I.V.) Laufzeit ch
> - Restliche Laufzeit ≤c
> ⇒ Laufzeit maximal ch+c = c(h+1).
>[!question] Satz
>Wenn die Unterbäume des rechten und linken Kindes von i die Heap-Eigenschaft besitzen, dann ist diese nach der Operation Heapify(A,i) für den Unterbaum von i erfüllt.
>[!info] Beweis:
>- Induktion über die Höhe von i.
>- (I.A.) Höhe 0 oder 1: Einfaches nachprüfen
>- (I.V.) Heapify erfüllt die Aussage des Satzes für Knoten i mit Höhe h.
>- (I.S.) Betrachte Aufruf Heapify(A,i) für Knoten i der Höhe h+1>1, wenn Unterbäume der Kinder von i bereits Heap Eigenschaft erfüllen
> - l und r: linkes bzw. rechtes Kind von i
> - Höhe von i>1
> ⇒ l und r kleiner als heap-size(A) ⇒ die an l und r gespeicherten Werte sind im Heap
> - Z. 3-5: Heapify(A,i) speichert Index von max{A[i], A[l], A[r]} in largest
> - Fallunterscheidung: A[i] ist Maximum / A[l] ist Maximum / A[r] ist Maximum
> - A[i] ist Maximum: Heap Eigenschaft ist bereits erfüllt; kein rekursiver Aufruf
> - A[l] ist Maximum (A[r] ist Maximum analog):
> - Unterbäume von l und r sind Heaps ⇒ A[l] und A[r] sind größte Elemente in ihren Unterbäumen
> - A[l] ist max{A[i], A[l], A[r]} ⇒ A[l] ist größtes Element im Unterbaum von i – Z. 6: A[i] wird mit A[l] getauscht
> - Z. 7: Aufruf von Heapify für Unterbaum von l; Höhe des Unterbaums ist h
> ⇒ Nach (I.V.): Nach Aufruf hat dieser Unterbaum Heap Eigenschaft
> - Bei i ist Max. aller Elemente gespeichert und rechter Unterbaum erfüllt Heap Eigenschaft
> ⇒ Unterbaum von i ist ein Heap
#### heap – Aufbau
- Idee:
- Jedes Blatt ist ein Heap
- Baue Heap "von unten nach oben" mit *Heapify* auf
$$
\begin{array}{l}
\textbf{Build-Heap}(A) \\
1.\ \ \text{heap-size}(A) \gets \text{length}(A) \\
2.\ \ \text{for } i \gets \lfloor \text{length}(A) / 2 \rfloor \text{ downto } 1 \text{ do} \\
3.\ \ \quad \text{Heapify}(A, i) \\
\end{array}
$$
>[!question] Satz
>Mit Hilfe des Algorithmus Build-Heap kann man einen Heap in O(n) Zeit aufbauen.
>[!info] Beweis (Korrektheit)
>- (Inv.) Unterbäume der Knoten größer als i besitzen die Heap Eigenschaft
>- Gilt insbesondere für die Unterbäume der Kinder von i
>- Aus vorherigen Satz folgt, dass Invariante durch Heapify aufrechterhalten wird
> - Satz:
> Wenn die Unterbäume des rechten und linken Kindes von i die Heap-Eigenschaft besitzen, dann ist diese nach der Operation Heapify(A,i) für den Unterbaum von i erfüllt.
>- Damit gilt am Ende der Schleife die Heap Eigenschaft für die Wurzel
>⇒ Build-Heap erzeugt Heap
>[!info] Beweis (Einfache Laufzeitanalyse)
>- Jedes Heapify benötigt $O(h) = O(\log n)$ Laufzeit.
>- Da es insgesamt $O(n)$ Heapify Operationen gibt, ist die Laufzeit $O(n \log n)$.
>[!info] Beweis (Schärfere Laufzeitanalyse)
>In einem Heap mit Höhe H gibt es maximal
> $2^0$ Knoten mit Höhe $H$,
> $2^1$ Knoten mit Höhe $H-1$,
> $2^2$ Knoten mit Höhe $H-2$,
> $\dots$
> $2^H$ Knoten mit Höhe $H-H = 0$ (Blätter)
>!200
>- D.h. wir bauen $2^H$ Heaps der Höhe $0$, $2^{H-1}$ Heaps der Höhe $1$, $…$, $2^0$ Heap der Höhe $H$ auf
>- Damit ergibt sich als Gesamtlaufzeit bei n Knoten und Höhe $H = \lfloor \log n \rfloor$:
> - $\mathcal{O}\left(H \cdot 2^0 + (H-1) \cdot 2^1 + \dots + (H-H) \cdot 2^H \right)$
> - $= \mathcal{O}\left(0 \cdot 2^H + 1 \cdot 2^{H-1} + \dots + (H-1) \cdot 2^1 + H \cdot 2^0 \right)$
> - $= \mathcal{O}\left(\sum_{h=0}^H h \cdot 2^{H-h} \right)$
> - $= \mathcal{O}\left(\sum_{h=0}^H \frac{h \cdot 2^H}{2^h} \right)$
> - $= \mathcal{O}\left(2^H \cdot \sum_{h=0}^H \frac{h}{2^h} \right)$
> - $= \mathcal{O}\left(n \cdot \sum_{h=0}^H \frac{h}{2^h} \right)$
#### Max Heap – Extract Max
- Die Wurzel (größtes Element aus einem Heap) wird ausgegeben und neu mit dem Wert des letzten Elements des Heaps `A[heap-size(A)]` zugewiesen. Anschließen wird der heap um die Länge 1 verringert und `Heapify(A,1)` ausgeführt, damit die Heap-Bedingung weiterhin erfüllt ist.
$$
\begin{array}{ll}
& \textbf{Heap-Extract-Max}(A): & \\
1. & \text{if } \text{heap-size}(A) < 1 \text{ then error "Kein Element vorhanden"} \\
2. & \text{max} \gets A[1] \\
3. & A[1] \gets A[\text{heap-size}(A)] \\
4. & \text{heap-size}(A) \gets \text{heap-size}(A) - 1 \\
5. & \text{Heapify}(A, 1) \\
6. & \text{return max}
\end{array}
$$
#### Max Heap – Einfügen
$$
\begin{array}{ll}
& \textbf{Heap-Insert}(A, \text{key}): & \\
1. & \text{heap-size}(A) \gets \text{heap-size}(A) + 1 \\
2. & i \gets \text{heap-size}(A) \\
3. & \text{while } i > 1 \text{ and } A[\text{Parent}(i)] < \text{key do} \\
4. & \quad A[i] \gets A[\text{Parent}(i)] \\
5. & \quad i \gets \text{Parent}(i) \\
6. & A[i] \gets \text{key}
\end{array}
$$
- Laufzeit: $O(\log(n))$
#### Heapsort
$$
\begin{array}{ll}
& \textbf{Heapsort}(A): & \\
1. & \text{Build-Heap}(A) \\
2. & \text{for } i \gets \text{length}(A) \text{ downto } 2 \text{ do} \\
3. & \quad A[1] \leftrightarrow A[i] \\
4. & \quad \text{heap-size}(A) \gets \text{heap-size}(A) - 1 \\
5. & \quad \text{Heapify}(A, 1)
\end{array}
$$
- Laufzeit: $O(n \log(n))$
- braucht keinen zusätzlichen Speicherplatz
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/avl-tree/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# AVL-Bäume
- Problem von Bäumen ist, dass ein binärer Suchbaum **degeneriert** (nicht balanciert) sein kann. Das hat zur folge, dass ein binary tree im worst case eine Liste ist. **Deswegen** gibt es AVL trees
- wenn man sicherstellt, dass die Höhe der Teilbäume ungefähr gleich ist, dann ist die Höhe des Baumes `O(log n)`
- AVL-Bäume wurde von **A**delson-**V**elsky und **L**andis entwickelt
- Ein binärer Baum heißt AVL-Baum, wenn für jeden Knoten gilt: Die Höhe seines linken und rechten Teilbaums unterscheidet sich höchstens um 1
- Durch Rotationen wird aus einem binären Suchbaum ein AVL-Baum
## Links- und Rechtsrotation
!introprog-v11-baeume-avl, p.53
- man stelle sich vor, dass die Elemente Murmeln und die Pointer Schnüre sind. Hält man einen balancierten Baum an der Wurzelmurmel fest, dann sind die Murmeln ganz unten etwa auf der selben höhe. ist das nicht so, so kann man die Kindmurmel der Wurzel auf der Seite des längeren teilbaumes anfassen, was dafür sorgt, dass der Baum balanciert wird.
- konkreter gesagt muss man bei einer Linksrotation im oberen Beispiel, b als neuen rechten Kindknoten von x festlegen. y wird der Vater von x und das linke Kind von y wird x.
$$
\begin{array}{ll}
&\textbf{Linkrotation}(x) & \\
1. & y \gets rc[x] \\
2. & rc[x] \gets lc[y] \\
3. & \textbf{if } lc[y] \neq \text{nil} \textbf{ then } p[lc[y]] \gets x \\
4. & p[y] \gets p[x] \\
5. & \textbf{if } p[x] = \text{nil} \textbf{ then } root[T] \gets y \\
6. & \textbf{else if } x = lc[p[x]] \textbf{ then } lc[p[x]] \gets y \\
7. & \textbf{else } rc[p[x]] \gets y \\
8. & lc[y] \gets x \\
9. & p[x] \gets y \\
\end{array}
$$
## Beinahe-AVL-Baum
>[!info] **Definition:**
>Ein Baum heißt beinahe-AVL-Baum, wenn die AVL-Eigenschaft in jedem Knoten außer der Wurzel erfüllt ist und sich die Höhe der Unterbäume der Wurzel um höchstens 2 unterscheidet.
$$
\begin{array}{ll}
& \textbf{Balance}(y) & \\
1. & \textbf{if } h[lc[y]] > h[rc[y]] + 1 \textbf{ then} \\
2. & \quad \textbf{if } h[lc[lc[y]]] < h[rc[lc[y]]] \textbf{ then} \\
3. & \quad \quad \text{Linkrotation}(lc[y]) \\
4. & \quad \text{Rechtsrotation}(y) \\
5. & \textbf{else if } h[rc[y]] > h[lc[y]] + 1 \textbf{ then} \\
6. & \quad \textbf{if } h[rc[rc[y]]] < h[lc[rc[y]]] \textbf{ then} \\
7. & \quad \quad \text{Rechtsrotation}(rc[y]) \\
8. & \quad \text{Linkrotation}(y) \\
\end{array}
$$
### Fall 1: Einfache Rechtsrotation
!introprog-v11-baeume-avl, p.71
### Fall 2: Doppelrotation
- B ist der Verursacher
!introprog-v11-baeume-avl, p.73
- Teile B in zwei Unterteile auf
!introprog-v11-baeume-avl, p.74
- Linksrotation
!introprog-v11-baeume-avl, p.75
- Rechtsrotation
!introprog-v11-baeume-avl, p.76
## Operationen
Notes
### Einfügen
$$
\begin{array}{r l}
& \text{\textbf{AVL-Einfügen(t,x)}} \\
1. & \textbf{if } t = \text{nil} \textbf{ then} \\
2. & \quad t \leftarrow \text{new node}(x); \quad h[t] \leftarrow 0; \quad \textbf{return} \\
3. & \textbf{else if } x < \text{key}[t] \textbf{ then } \text{AVL-Einfügen}(\text{lc}[t], x) \\
4. & \textbf{else if } x > \text{key}[t] \textbf{ then } \text{AVL-Einfügen}(\text{rc}[t], x) \\
5. & \textbf{else return} \quad \triangleright \text{ Schlüssel schon vorhanden} \\
6. & h[t] \leftarrow 1 + \max \{ h[\text{lc}[t]], h[\text{rc}[t]] \} \\
7. & \text{Balance}(t) \\
\end{array}
$$
logarithmische **Laufzeit:** `O(h) = O(log n)`
### Löschen
$$
\begin{array}{r l}
& \text{\textbf{AVL-Löschen(t,x)}} \\
01. & \textbf{if } t = \text{nil} \textbf{ then return} \quad \triangleright \text{ x nicht im Baum} \\
02. & \textbf{else if } x < \text{key}[t] \textbf{ then } \text{AVL-Löschen}(\text{lc}[t], x) \\
03. & \textbf{else if } x > \text{key}[t] \textbf{ then } \text{AVL-Löschen}(\text{rc}[t], x) \\
04. & \textbf{else if } \text{lc}[t] = \text{nil} \textbf{ then} \text{ ersetze } t \text{ durch } \text{rc}[t] \\
05. & \textbf{else if } \text{rc}[t] = \text{nil} \textbf{ then} \text{ ersetze } t \text{ durch } \text{lc}[t] \\
06. & \textbf{else } u = \text{MaximumSuche}(\text{lc}[t]) \\
07. & \quad \text{Kopiere Informationen von } u \text{ nach } t \\
08. & \quad \text{AVL-Löschen}(\text{lc}[t], \text{key}[u]) \\
09. & \textbf{if } t \neq \text{nil} \textbf{ then } h[t] = 1 + \max \{ h[\text{lc}[t]], h[\text{rc}[t]] \} \\
10. & \text{Balance}(t) \\
\end{array}
$$
## Beweis für Höhe
>[!important] **Satz:**
>Für jeden AVL-Baum der Höhe $h≥0$ mit n Knoten gilt: $(3/2)^h ≤ n ≤ 2^{h+1} -1$
>[!success] **Beweis:** durch Fallunterscheidung
>- a) $n ≤ 2^{h+1} -1$ (obere Schranke)
> - AVL-Baum ist Binärbaum
> - Ein vollständiger Binärbaum hat eine maximale Anzahl Knoten unter allen Binärbäumen der Höhe h
> - `N(h)` = Anzahl Knoten eines vollständigen Binärbaums der Höhe h
> - $N(h) = 1+2+3+4\dots+2^k = \sum_{i=0}^h 2^{i} = 2^{h+1} -1$
>
>* b) $(3/2)^h ≤ n$ (untere Schranke)
> - Beweis per Induktion über die Struktur von AVL-Bäumen
> - (I.A.) Wir betrachten alle AVL-Bäume der Höhe $0$ und $1$.
> - $h=0$: Der Baum hat einen Knoten. Es gilt $(3/2)^h = 1 ≤ 1$.
> - $h=1$: Der Baum hat 2 oder 3 Knoten. Es gilt $(3/2)^h = 3/2 ≤ 2 ≤ 3$.
> - (I.V.) Für jeden AVL-Baum der Höhe $j, 0 ≤ j ≤ h$, gilt der Satz.
> - (I.S.) Sei $h≥1$. Betrachte AVL-Baum $T$ der Höhe $h+1$ mit Wurzel $v$.
> - Seien $A,B$ linker bzw. rechter Teilbaum von $v$.
> - $A$ oder $B$ (oder beide) hat Tiefe $h$.
> - Wegen AVL-Eigenschaft haben $A$ und $B$ Tiefe mindestens $h-1≥0$.
> - Da $T$ ein AVL-Baum ist, sind auch $A$ und $B$ AVL-Bäume.
> - Wir können (I.V.) anwenden, da $A$ und $B$ AVL-Bäume der Tiefe $≥0$ sind
> - Es gibt drei Fälle:
> 1) $A,B$ haben Höhe $h$
> 2) $A$ hat Höhe $h$ und $B$ hat Höhe $h-1$
> 3) $A$ hat Höhe $h-1$ und $B$ hat Höhe $h$
> - Sei $T(h)$ die minimale Anzahl Knoten in einem AVL-Baum der Tiefe $h$.
> - Nach (I.V.) gilt in allen drei Fällen
> $$ \begin{array}{rl} T(h+1) & \geq T(h) + T(h-1) + 1 &\geq \left(\frac{3}{2}\right)^h + \left(\frac{3}{2}\right)^{h-1} + 1 \\ & \geq \left(1 + \frac{3}{2}\right) \cdot \left(\frac{3}{2}\right)^{h-1} & \geq \left(\frac{3}{2}\right)^2 \cdot \left(\frac{3}{2}\right)^{h-1} &= \left(\frac{3}{2}\right)^{h+1}. \end{array}$$
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/divide-and-conquer/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# divide & conquer
>[!tldr] Prinzp
>- Teile Eingabe in mehrere Teile auf
>- Löse das Problem rekursive auf den Teilen
>- Füge die Teillösungen zu einer Gesamtlösung zusammen
## Mastertheorem
>[!important] Fall 1
>Laufzeit auf **unterster Rekursionsstufe** *dominiert*: **$O(n^{\log_{b}(a)})$**
>[!important] Fall 2
>Laufzeiten **zusammensetzen** und **Rekursion** *vergleichbar*: $O(n^{\log_{b}(a)} \cdot \log(n))$
>[!important] Fall 3
>Laufzeit **zusammensetzen** *dominiert*: $O(f(n))$
## Basics
>[!faq] wodurch unterscheiden sich Teile & Herrsche Algorithmen?
>- Anzahl der Teilprobleme
>- Die Größe der Teilprobleme
>- Den Algorithmus für das Zusammensetzen der Teilproblem
>- Den Rekursionsabbruch
>[!faq] wann lohnt sich Teile & Herrsche?
>- Kann durch Laufzeitanalyse vorhergesagt werden
>- Wovon hängt die Laufzeit ab?
> - Anzahl der Teilprobleme
> - Größe der Teilprobleme
> - Algorithmus für das Zusammensetzen der Teilprobleme
## Rekursionsgleichung
- Rekursionsgleichung von Teile & Herrsche lautet immer $T(n) = a \cdot T\left( \frac{n}{b} \right) + f(n)$
- $a$ := Anzahl der Unterprobleme
- $T\left( \frac{n}{b} \right)$ := Größe der Unterprobleme (bestimmt Höhe des Rekursionsbaums)
- $f(n)$ := Aufwand für Aufteilen und Zusammenfügen
- Rekursionsgleichung Mergesort
- $t(n) = 2 \cdot T\left( \frac{n}{2} \right) + c \cdot n$
## binäre Suche
- **Problem:** Finde Element b in sortiertem Feld
- **Algorithmus:** binäre Suche
#### **Prinzip:**
- Suche:
- Vergleiche Element b mit dem mittleren Element des Feldes
- *wenn gefunden, gib Feldindex zurück*
- wenn kleiner, dann such rekursiv im linken Teilfeld
- wenn größer, dann suche rekursiv im rechten Teilfeld
- Abbruchbedingung:
- wenn Feldgröße == 0, gib "Element nicht gefunden" zurück
- wenn gefunden, gib Feldindex zurück
### vereinfachte binäre Suche mit Annahme b ist im Feld A
- Problem: Finde Index des Elements b in sortiertem Feld
- Annahme: Element vorhanden, d.h. b existiert im sortierten Feld
- Algorithmus Vereinfachte binäre Suche
#### Prinzip:
- Suche
- Vergleiche Element b mit dem mittleren Element des Feldes
- wenn kleiner, dann suche rekursiv im linken Teilfeld
- wenn größer, dann suche rekursiv im rechten Teilfeld
- Abbruchbedingung;
- Wenn Feldgröße == 1, gib den Index zurück
#### Algorithmus:
$$
\begin{array}{ll}
& \textbf{BinäreSuche}(A, b, p, r) \quad \text{ // A Feld, b Element, p Feldanfang, r Feldende} \\
1. & \textbf{if } p = r \textbf{ then return } p \\
2. & \textbf{else} \\
3. & \quad q \gets \lfloor (p + r) / 2 \rfloor \\
4. & \quad \textbf{if } b \leq A[q] \textbf{ then return } \textbf{BinäreSuche}(A, b, p, q) \\
5. & \quad \textbf{else return } \textbf{BinäreSuche}(A, b, q+1, r)
\end{array}
$$
#### beweis
>[!important] **Satz:** Algorithmus `BinäreSuche(A,b,p,r)` findet den Index einer Zahl b in einem sortierte Feld `A[p..r]`, sofern $b$ in `A[p..r]` vorhanden ist.
>[!success] **Beweis:** per Induktion über $n=r-p$
> - (I.A.) Für $n=0$, d.h. $p=r$, gibt der Algorithmus $p$ zurück. Dies ist der korrekte (weil einzige) Index.
>- (I.V.) Für alle $r,p$ mit $m=r-p$ und $0≤m≤n$ findet `BinäreSuche(A,b,p,r)` den Index einer Zahl $b$ in einem sortierten Feld A[p..r], sofern b im Feld vorhanden ist.
>- (I.S.) Wir betrachten den Aufruf von BinäreSuche für beliebige $p$, $r$ mit $n+1 = r-p$
> - Da $n+1>0$ folgt $p<r$ und der Algorithmus führt den ersten else-Fall aus.
> - Dort wird q auf $\lfloor (p+r)/2 \rfloor$ gesetzt. – Es gilt $q≥p$ und $q<r$.
> - Ist $b≤A[q]$, so wird BinäreSuche rekursiv für $A[p..q]$ aufgerufen.
> - Da $A[p..r]$ sortiert ist, liegt $b$ in $A[p..q]$.
> - Damit folgt aus (I.V.), dass der Index von $b$ gefunden wird.
> - Ist $b>A[q]$, so wird BinäreSuche rekursiv für $A[q+1..r]$aufgerufen.
> - Da $A[p..r]$ sortiert ist, liegt $b$ in $A[q+1..r]$.
> - Damit folgt aus (I.V.), dass der Index von $b$ gefunden wird.
#### Laufzeit
$$
\begin{array}{ll}
1. & \textbf{if } p = r \textbf{ then return } p & 1\\
2. & \textbf{else} & 1\\
3. & \quad q \gets \lfloor (p + r) / 2 \rfloor & 1\\
4. & \quad \textbf{if } b \leq A[q] \textbf{ then return } \textbf{BinäreSuche}(A, b, p, q) & 1 + T(\lfloor n/2 \rfloor) \\
5. & \quad \textbf{else return } \textbf{BinäreSuche}(A, b, q+1, r) & 1 + T(\lceil n/2 \rceil) \\ \\
&& 5 + \max\{T(\lfloor n/2 \rfloor), T(\lceil n/2 \rceil)\} \\
\end{array}
$$
$$
\textbf{Laufzeit: } T(n) =
\begin{cases}
1, & \text{falls } n = 1 \\
5 + \max\{T(\lfloor n/2 \rfloor), T(\lceil n/2 \rceil)\}, & \text{falls } n > 1
\end{cases}
$$
#### Rekursionsgleichung: $T(n)= 1 \cdot T\left( \frac{n}{2} \right) + c$
!introprog-v12-teile-herrsche-die-zweite, p.91
### Binäre Suche ohne Annahme
- **Problem:**Finde Element b in sortiertem Feld
- **Eingabe:** Sortiertes Feld A, gesuchtes Element b
- **Ausgabe:** Index `i` mit `A[i]` = b oder -1 (für nicht gefunden)
#### Algorithmus
$$
\begin{array}{ll}
1. & \textbf{if } p = r \textbf{ and } A[p] = b \textbf{ then return } p \quad // \text{Element gefunden} \\
2. & \textbf{else if } p = r \textbf{ and } A[p] \neq b \textbf{ then return } -1 \quad // \text{Element nicht gefunden} \\
3. & \textbf{else} \\
4. & \quad q \gets \lfloor (p + r) / 2 \rfloor \\
5. & \quad \textbf{if } b \leq A[q] \textbf{ then return } \textbf{BinäreSuche}(A, b, p, q) \quad // \text{links} \\
6. & \quad \textbf{else return } \textbf{BinäreSuche}(A, b, q+1, r) \quad // \text{rechts}
\end{array}
$$
### binäre Suche vs. lineare Suche
| Laufzeit | 10 | 100 | 1.000 | 10.000 | 100.000 |
| -------- | --- | --- | ----- | ------ | ------- |
| n | 10 | 100 | 1.000 | 10.000 | 100.000 |
| log n | 3 | 6 | 10 | 13 | 17 |
## Integer Multiplikation
- Problem: Multipliziere zwei n-Bit Integer
- Eingabe: Zwei n-Bit Integer X,Y
- Ausgabe: 2n-Bit Integer Z mit Z=XY
- Annahmen:
- Wir können n-Bit Integer in Θ(n) (worst case) Zeit addieren
- Wir können n-Bit Integer in Θ(n+k) (worst case) Zeit mit $2^k$ multiplizieren (durch Shift)
### Schulmethode (binär)
- !200
- Laufzeit: $O(n^2)$
### mit Teile & Herrschen
#### Einfaches Teile und Herrsche
- !introprog-v12-teile-herrsche-die-zweite, p.124
- Laufzeit: $T(n) = 4 \cdot T\left( \frac{n}{2} \right) +cn$
!introprog-v12-teile-herrsche-die-zweite, p.146
#### verbessertes Teile und Herrsche
- !introprog-v12-teile-herrsche-die-zweite, p.149
- $(a+B)(C+D) -AC -BD = BC + AD$
- Laufzeit: $3 T\left( \frac{n}{2} \right) +cn$
!introprog-v12-teile-herrsche-die-zweite, p.179
- Laufzeitgewinn
| Laufzeit | 10 | 100 | 1.000 |
| ---------- | ---- | ------ | --------- |
| $n^2$ | 100 | 10.000 | 1.000.000 |
| $n^{1,59}$ | 39 | 1.514 | 58.885 |
| **Faktor** | 2,56 | 6,6 | 17 |
!introprog-v12-teile-herrsche-die-zweite, p.180
</div></div>
***
####
<div class="transclusion internal-embed is-loaded"><a class="markdown-embed-link" href="/07-spaces/work-and-education/2-areas/min-tgruen/24-25-wi-se/einfuehrung-ins-programmieren/synthesis-notes/quicksort/" aria-label="Open link"><svg xmlns="http://www.w3.org/2000/svg" width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="svg-icon lucide-link"><path d="M10 13a5 5 0 0 0 7.54.54l3-3a5 5 0 0 0-7.07-7.07l-1.72 1.71"></path><path d="M14 11a5 5 0 0 0-7.54-.54l-3 3a5 5 0 0 0 7.07 7.07l1.71-1.71"></path></svg></a><div class="markdown-embed">
# Quicksort
- nutzt das Prinzip "divide-and-conquer"
>[!abstract] Arbeitsweise
>1. **Pivot-Auswahl:** Wähle ein Element als Pivot (z. B. low).
>2. **Partitionierung:** Ordne das Array so um, dass alle Elemente, die kleiner oder gleich dem Pivot sind, links und alle, die größer sind, rechts angeordnet werden. Am Ende der Partitionierung steht der Pivot an seiner endgültigen Position.
>3. **Rekursion:** Wende diesen Vorgang rekursiv auf die beiden Teillisten (links und rechts vom Pivot) an, bis die Listen 0 oder 1 Element enthalten.
!introprog-v10-sortieren-teil2, p.7
## Komplexität
- Wenn es gelingt, die Teilfolgen durch das Gruppieren jeweils zu halbieren, erhalten wir eine Komplexität von: $T_{bc} = O(n \log n)$
- $T_{bc}$ bedeutet best case
- Wird jeweils nur eine Teilfolge konstanter Länge abgespalten, so wird n mal gruppiert und daher: $T_{wc} = O(n^2)$
- $T_{wc}$ bedeutet worst case
- Im Durchschnitt ist allerdings die Länge der Intervalle abhängig von n und man braucht nur zweimal mehr Operationen als im besten Fall: $T_{ac} = O(n \log n)$
- $T_{ac}$ bedeutet average case
## Varianten
- Vorgeschlagene Varianten betreffen die Wahl des Trennwerts für das Gruppieren, der in der vorliegenden Form für das schlechte Verhalten bei nahezu sortierten Folgen verantwortlich ist:
1. Trennindex zufällig aus `[start, end]`
2. Trennwert als Median aus drei Elementen $\{f_{\text{start}}, f\lvert{\frac{\text{start} + \text{end}}{2}}\rvert, f_{\text{end}}\}$
- Beide Varianten haben sich gut bewährt und sorgen auch bei fast sortierten Folgen für O(n log n).
- Es ist außerdem vorteilhaft, die kleinere Teilfolge zuerst zu sortieren (Rekursionstiefe minimieren)
## Quick Sort mit Listen
- Zerlegen einer Folge in zwei Teilfolgen, wovon die eine die kleineren (<) Elemente, die andere die größeren (≥) Elemente enthält
- Als Trennwert (pivot) wird oft der Wert des ersten Elements genommen.
- Statt des Vertauschens (swap) werden die Elemente in zwei neue Listen (left, right) versetzt (move).
- Diese werden dann rekursiv sortiert und zu der Resultatliste zusammengesetzt.
- Die Komplexität des Gruppierungsverfahrens ist, wie bei den Arrays, O(n), da die Liste genau einmal abgelaufen wird und jeweils konstanter Aufwand entsteht
## Beispiele
### Beispiel 1 (aus Vorlesung)
- vor Gruppieren
!introprog-v10-sortieren-teil2, p.11
- Partition
!introprog-v10-sortieren-teil2, p.13
!introprog-v10-sortieren-teil2, p.14
- Quicksort
!introprog-v10-sortieren-teil2, p.16
!introprog-v10-sortieren-teil2, p.17
!introprog-v10-sortieren-teil2, p.18
!introprog-v10-sortieren-teil2, p.19
### Beispiel 2 (Wikipedia)
- Beispiel an einem Array
!300
- Quicksort mit Array
- Pivot: letztes Element (dunkler Hintergrund)
- Arrays werden von links nach rechts abgearbeitet
- Statt linker und rechter Liste: Ringtausch
## Stabilität
Quicksort ist nur dann stabil, wenn alle Elemente mit dem gleichen Wert des gewählten Pivots, die vor bzw. nach dem Pivot kommen, auch entsprechend in die linke bzw. rechte Liste gehen.
## Pseudocode
$$
\begin{array}{rl}
& \textbf{QuickSort (list to sort)} \\
1. & \text{// Abbruchbedingung} \\
2. & \text{if (tosort.first = tosort.last)} \\
3. & \quad \text{return} \\
4. & \text{else} \\
5. & \quad \text{list left, right} \\
6. & \quad \text{pivot $\gets$ Partition(tosort, left, right)} \\
7. & \quad \text{// Rekursion} \\
8. & \quad \text{QuickSort(left)} \\
9. & \quad \text{QuickSort(right)} \\
10. & \text{// Listen zusammenfügen} \\
11. & \text{if (left.first = NULL) // Test auf Gleichheit!} \\
12. & \quad \text{tosort.first $\gets$ pivot} \\
13. & \quad \text{tosort.last $\gets$ pivot} \\
14. & \text{else} \\
15. & \quad \text{tosort.first $\gets$ left.first} \\
16. & \quad \text{left.last.next $\gets$ pivot} \\
17. & \text{if (right.first = NULL) // Test auf Gleichheit!} \\
18. & \quad \text{pivot.next $\gets$ NULL} \\
19. & \quad \text{tosort.last $\gets$ pivot} \\
20. & \text{else} \\
21. & \quad \text{pivot.next $\gets$ right.first} \\
\end{array}
$$
## Quick Sort in C
```c
// C program to implement Quick Sort Algorithm
#include <stdio.h>
void swap(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
int partition(int arr[], int low, int high) {
// Initialize pivot to be the first element
int p = arr[low];
int i = low;
int j = high;
while (i < j) {
// Find the first element greater than
// the pivot (from starting)
while (arr[i] <= p && i <= high - 1) {
i++;
}
// Find the first element smaller than
// the pivot (from last)
while (arr[j] > p && j >= low + 1) {
j--;
}
if (i < j) {
swap(&arr[i], &arr[j]);
}
}
swap(&arr[low], &arr[j]);
return j;
}
void quickSort(int arr[], int low, int high) {
if (low < high) {
// call partition function to find Partition Index
int pi = partition(arr, low, high);
// Recursively call quickSort() for left and right
// half based on Partition Index
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
int main() {
int arr[] = { 4, 2, 5, 3, 1 };
int n = sizeof(arr) / sizeof(arr[0]);
// calling quickSort() to sort the given array
quickSort(arr, 0, n - 1);
for (int i = 0; i < n; i++)
printf("%d ", arr[i]);
return 0;
}